Camera Intrinsic Models for Project Aria devices
This page provides an overview of the intrinsic models used by RGB, Eye Tracking and Mono Scene (aka SLAM) cameras in Project Aria glasses. Go to the Project Aria FAQ for more calibration information and resources.
A camera intrinsic model maps between a 3D world point in the camera coordinate and its corresponding 2D pixel on the sensor. It supports mapping from the 3D point to the pixel (projection) and from the pixel to the ray connecting the point and the camera's optical center.
Our projection models are based on polar coordinates of 3D world points. Given a 3D world point in the device frame , we first transform it to the camera's local frame
the corresponding polar coordinates that satisfies
We assume the camera has a single optical center and thus all points of the same polar coordinate maps to the same 2D pixel :
Here is the camera projection model.
Inversely, we can unproject from a 2D camera pixel to the polar coordinate by
In Aria we support four types of project models, Linear, Spherical, KannalaBrandtK3, and FisheyeRadTanThinPrism. The linear camera model are standard textbook intrinsic models and good for image rectification. However, cameras on the Aria glasses all have fisheye lenses, and spherical camera model are much better approximations for these glasses. In order to calibrate the camera lenses at a high quality, we use two more sophisticated camera models to add modeling of radial and tangential distortions.
The next table shows which model is used for each type of Aria camera:
| Camera Type | Intrinsics Model |
|---|---|
| Slam Camera | FisheyeRadTanThinPrism |
| Rgb Camera | FisheyeRadTanThinPrism |
| Eye-Tracking Camera | KannalaBrandtK3 |
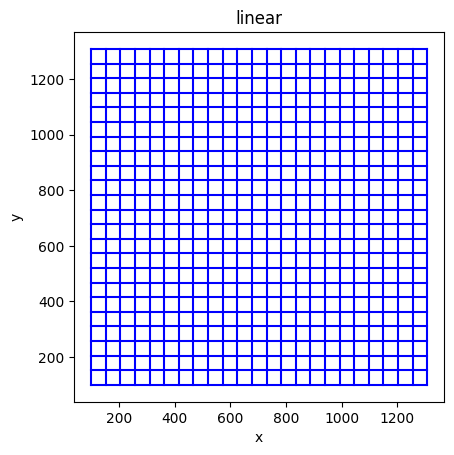
The linear camera model
The linear camera model (a.k.a pinhole model) is parametrized by 4 coefficients : f_x, f_y, c_x, c_y.
are the focal lengths, and are the coordinate of the projection of the optical axis. It maps from world point to 2D camera pixel with the following formulae.
Or, in polar coordinates:
Inversely, we can unproject from 2D camera pixel to the homogeneous coordinate of the world point by
The linear camera model preserves linearity in 3D space, thus straight lines in the real world are supposed to look straight under the linear camera model.
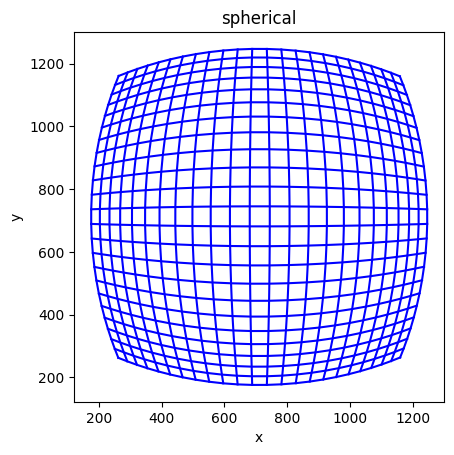
The spherical camera model
The spherical camera model is, similarly from the linear camera model parametrized by 4 coefficients : f_x, f_y, c_x, c_y. The pixel coordinates are linear to solid angles rather than the homography coordinate system. The projection function can be written in polar coordinates
Note the difference from the linear camera model — under spherical projection, 3D straight lines look curved in images.
Inversely, we can unproject from 2D camera pixel to the homogeneous coordinate of the world point by
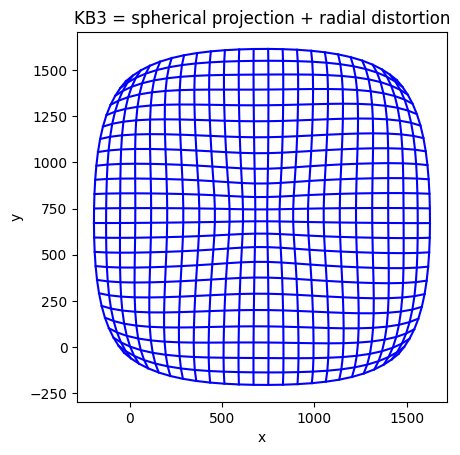
The KannalaBrandtK3 (KB3) model
The KannalaBrandtK3 model adds radial distortion to the linear model
where
In KannalaBrandtK3 model we use a 9-th order polynomial with four radial distortion parameters .
To unproject from camera pixel to the world point , we first compute
Then we use Newton method to inverse the function to compute . See the code here.
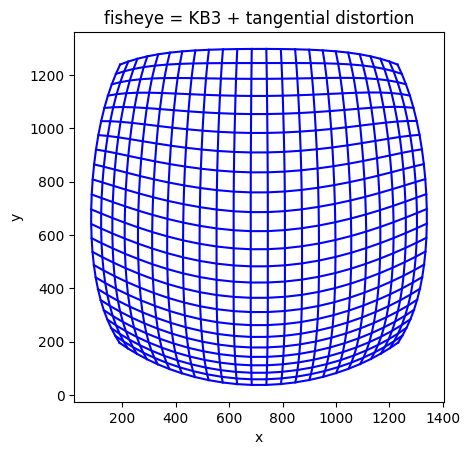
The Fisheye62 model
The Fisheye62 model adds tangential distortion on top of the KB3 model parametrized by two new coefficients: p_0 p_1.
where
and
To unproject from camera pixel to the world point , we first use Newton method to compute and from and , and then compute using the above KB3 unproject method.
The FisheyeRadTanThinPrism (Fisheye624) model
The FisheyeRadTanThinPrism (also called Fisheye624 in file and codebase) models thin-prism distortion (noted ) on top of the Fisheye62 model above. Its parametrization contains 4 additional coefficients: s_0 s_1 s_2 s_3. The projection function writes:
u_r, v_r, t_x, t_y are defined as in the Fisheye62 model, while and are defined as:
To unproject from camera pixel to the world point , we first use Newton method to compute and from and , and then compute using the above KB3 unproject method.
Note that in practice, in our codebase and calibration file we assume and are equal.