Example: Video Classification¶
This page walks through a complete autoresearch run on the video
classification example pipeline in spdl/examples/video_classification.
The engine ran for approximately 23 hours, executed 120 experiments, and
reduced step time from 426ms to 153ms — a 2.78× speedup.
Setup¶
Pipeline: Video classification training with R3D-18 on Kinetics-400. The baseline data pipeline uses SPDL PipelineBuilder with the following stages:
Sampling → fetch → decode (FFmpeg, CPU) → aggregate → collate → GPU transfer
Hardware: 1×8 H100 GPUs.
Engine configuration:
python run.py /tmp/video_classification_opt \
--pipeline-script spdl/examples/video_classification/video_classification.py \
--source-dir spdl/examples/video_classification \
--build-command "docker build -t my_image ." \
--base-launch-command "torchx run ... --img \$IMAGE -j 1x8 ..." \
--max-iterations 20 --patience 5 --max-concurrency 4 --job-timeout 600
The engine ran with up to 4 concurrent experiments and a 10-minute timeout per job. The run was based on commit 3bf24e7.
Baseline¶
The unmodified pipeline produced 426ms/step with 5.75% GPU SM utilization. The headspace analysis (CacheDataLoader) measured a compute floor of 29.8ms/step — 93% of step time was spent waiting for data. Video decoding was the dominant bottleneck by a wide margin.
The MTP (subprocess pipeline) seed experiment failed: the dataset object is not picklable, so the pipeline could not be moved to a subprocess. This meant all optimization had to happen within the main process.
Results¶
The best configuration (run 101_optimal_consolidated) achieved
153ms/step, a 64.1% reduction from baseline. The result was
independently confirmed by a reproduction run. The optimized pipeline
is available in the repository at commit b1d98c5.
Optimization |
Step Time |
Cumulative Improvement |
|---|---|---|
Baseline (CPU FFmpeg, concurrency=16) |
426ms |
— |
+ GPU NVDEC decode (concurrency=14) |
308ms |
↓27.7% |
+ Split demux/decode pipeline |
280ms |
↓34.3% |
+ Optimal NVDEC concurrency=7 (1:1 HW slots) |
280ms |
↓34.3% |
+ Subclip 2s temporal windowing |
195ms |
↓54.2% |
+ bf16 autocast + fused optimizer |
184ms |
↓56.8% |
+ Dedicated thread executors |
171ms |
↓59.9% |
+ Fetch concurrency=4 + build threads tuning |
170ms |
↓60.1% |
All consolidated |
153ms |
↓64.1% |
Key Discoveries¶
What worked¶
GPU NVDEC decode — The single biggest win. Replacing CPU FFmpeg with the H100’s dedicated NVDEC hardware video decoders reduced per-item decode time from 0.85s to 0.54s at concurrency=14, and to 0.245s at concurrency=7 with zero hardware contention.
Optimal NVDEC concurrency = 7 — H100 has 7 NVDEC instances. A 1:1 mapping (concurrency=7) gives zero hardware contention. Oversubscription degrades throughput: concurrency=14 doubles per-item latency (0.54s) but doubles parallelism, netting the same 280ms step time. At concurrency=20+, the regression is severe.
Split demux/decode pipeline — Separating CPU demuxing from GPU NVDEC decode into distinct pipeline stages enables CPU-GPU overlap, yielding ~9% improvement over monolithic NVDEC.
Subclip 2s temporal windowing — Limiting video segment length to 2s reduces NVDEC decode work by roughly 2× (0.245s → 0.120s per item). 2.0s is the optimal duration — shorter durations add demux seeking overhead, longer durations increase decode time.
Dedicated thread executors — Outperformed
PriorityThreadPoolExecutorby 7% (171ms vs 184ms) by eliminating pool contention between stages. Configuration: 8 threads for demux, 8 for fetch, 7 for NVDEC decode.bf16 autocast + fused optimizer — Added ~2.5% compute savings. Small individually, but real when stacked with other optimizations.
What did not work¶
Larger batch sizes — Always hurt in decode-bottlenecked pipelines. NVDEC hardware produces a fixed ~28 items/s/rank; larger batches mean fewer batches per second (batch=16: ↓11.5%, batch=32: ↓20.7%).
MTP (subprocess isolation) — The dataset object is fundamentally not picklable. The Tier 2 workaround (callable classes) achieved only 4.2% gain.
NVDEC oversubscription (concurrency > 14) — Per-item decode time scales poorly: concurrency=20 adds +100% latency, concurrency=28 adds +200%, concurrency=35 crashes on init.
torch.compile — Zero steady-state improvement (compute is only 15% of step time) but adds ~76s compilation warmup.
mode='reduce-overhead'crashed during CUDA graph capture.DDP optimization flags (
static_graph,gradient_as_bucket_view) — Zero measurable effect. DDP overhead is <1% of step time.GC management — Crashed on startup 4 consecutive times. When it finally ran, it provided 0% throughput improvement.
Progress¶
The following plot shows experiment duration, step time, SM utilization, and raw SM utilization across all 120 experiments. Green dots mark improvements over the running best. The dashed blue line shows the headspace floor (29.8ms compute-only step time).
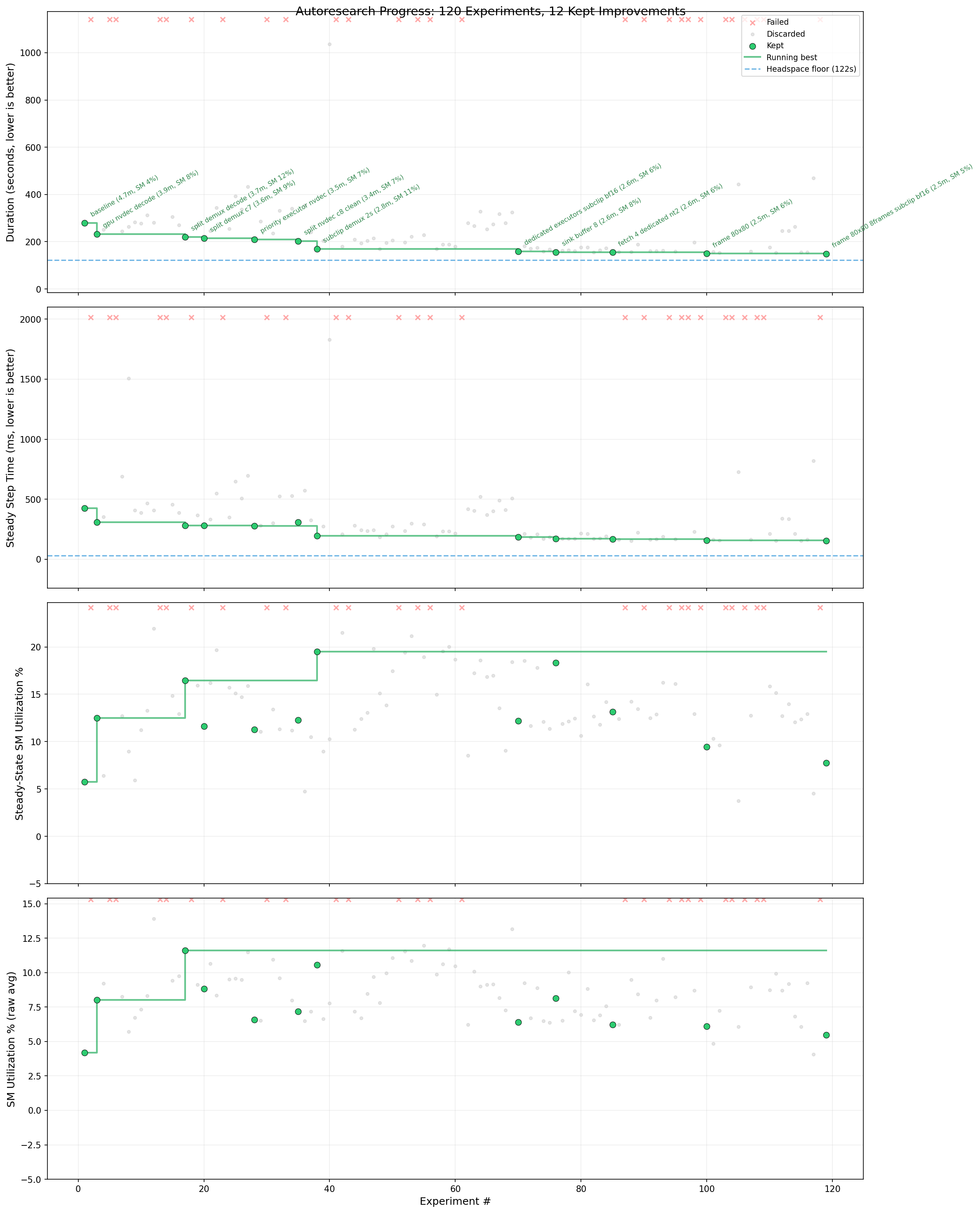
Step time dropped sharply in the first 30 experiments as the engine discovered GPU NVDEC decode and the split demux/decode pipeline. Subsequent experiments fine-tuned concurrency, temporal windowing, and executor configuration to push step time from ~280ms down to 153ms.
Hypothesis Tree¶
The full experiment tree shows how the engine explored the optimization space. Each node is an experiment; edges connect parent experiments to follow-ups proposed by the coding agent. Green nodes are kept improvements, gray nodes are completed without improvement, and red nodes are failures.
Starting from three seed experiments (baseline, headspace, MTP), the
tree branched into GPU NVDEC decode early — the engine identified
CPU video decoding as the dominant bottleneck within the first few
experiments. From there, it explored concurrency tuning, pipeline
splitting, temporal windowing, and compute optimizations. Failed
experiments (red nodes) include NVDEC oversubscription,
torch.compile crashes, and GC management attempts. The best path
runs through NVDEC decode → split demux/decode → subclip 2s → bf16
autocast → dedicated executors → consolidated optimal.
Remaining Headspace¶
Compute floor (CacheDataLoader) |
29.8ms |
Best achieved |
153ms |
Remaining headspace |
~80% |
Bottleneck |
NVDEC hardware decode rate (~28 items/s/rank) |
The 153ms result is at the NVDEC hardware throughput ceiling. Further improvement would require a fundamentally different approach to video decoding: a pre-decoded dataset, a codec with faster decode characteristics, multi-node decode distribution, or reduced spatial resolution.
Experiment Statistics¶
Total experiments |
120 |
Completed |
89 |
Failed (job stalled) |
5 |
Failed (runtime error) |
17 |
Failed (planning) |
4 |
Failed (analysis) |
1 |
Kept improvements |
12 |
Total nodes explored |
116 |
The engine ran 120 experiments over approximately 23 hours with up to
4 concurrent jobs. Of the 89 that completed successfully, 12 produced
kept improvements — a 13% hit rate on completed experiments. The 31
failures are a natural part of the search: the engine tries aggressive
configurations (high NVDEC oversubscription, torch.compile with
CUDA graphs, GC tuning) knowing that some will crash. Each failure
narrows the search space and informs subsequent planning.