Pipeline Parallelism¶
The Pipeline class supports multi-threading and multi-processing.
You can also use a Pipeline object as the source iterator of another
Pipeline.
When experimenting, this flexibility makes it easy to switch multi-threading,
multi-processing and mixtures of them.
This page covers the fundamentals: the executor mechanism, dedicated thread
pools, the cost of crossing a process boundary, the
to() region API, and
run_pipeline_in_subprocess(). For the higher-level patterns that
combine these primitives into an efficient data loader (MT, MP and MTP), see
Execution Models: MT, MTP, and MP.
Specifying an executor¶
The core mechanism to deploy concurrency is asyncio.loop.run_in_executor()
method. The synchronous function (or generator) provided to Pipeline
is executed asynchronously using the run_in_executor method.
When you provide a synchronous function (or generator), the PipelineBuilder
internally converts it to an asynchronous equivalent using the
run_in_executor method.
In the following snippet, an executor argument is provided when constructing
the Pipeline.
executor: ThreadPoolExecutor | ProcessPoolExecutor | None = ...
def my_func(input):
...
pipeline = (
PipelineBuilder()
.add_source(...)
.pipe(my_func, executor=executor)
.add_sink(...)
.build(...)
)
Internally, the my_func function is converted to an asynchronous equivalent,
meaning it’s dispatched to the provided executor (or a default one if the executor
is None) as follows.
async asynchronous_my_func(input):
loop = asyncio.get_running_loop()
coroutine = loop.run_in_executor(executor, my_func, input)
return await coroutine
Multi-threading (default)¶
If you build a pipeline without any customization, it defaults to multi-threading.
The event loop dispatches the tasks to the default
ThreadPoolExecutor
created with the maximum concurrency specified in PipelineBuilder.build()
method.
Note
Multi-threading characteristics:
All threads (main thread and worker threads) run within a single process and naturally share the same memory address space
Fast task startup and minimal overhead
Data can be passed by reference (no copying needed) with fast inter-thread communication
Constrained by the GIL for Python code - best for I/O-bound tasks or GIL-releasing operations
GIL considerations:
To take advantage of multi-threading, your stage functions must mainly
consist of operations that release the GIL. Libraries such as PyTorch and
NumPy release the GIL when manipulating arrays, and SPDL offers efficient
GIL-releasing functions for decoding raw bytes through the spdl.io
module. See Working Around the GIL for which libraries release the GIL,
and what to do when a stage’s function does not.
Multi-threading (custom)¶
There are cases where you want to use a dedicated thread for certain task.
You need to maintain a state across multiple task invocations. (caching for faster execution or storing the application context)
You want to specify a different number of concurrency.
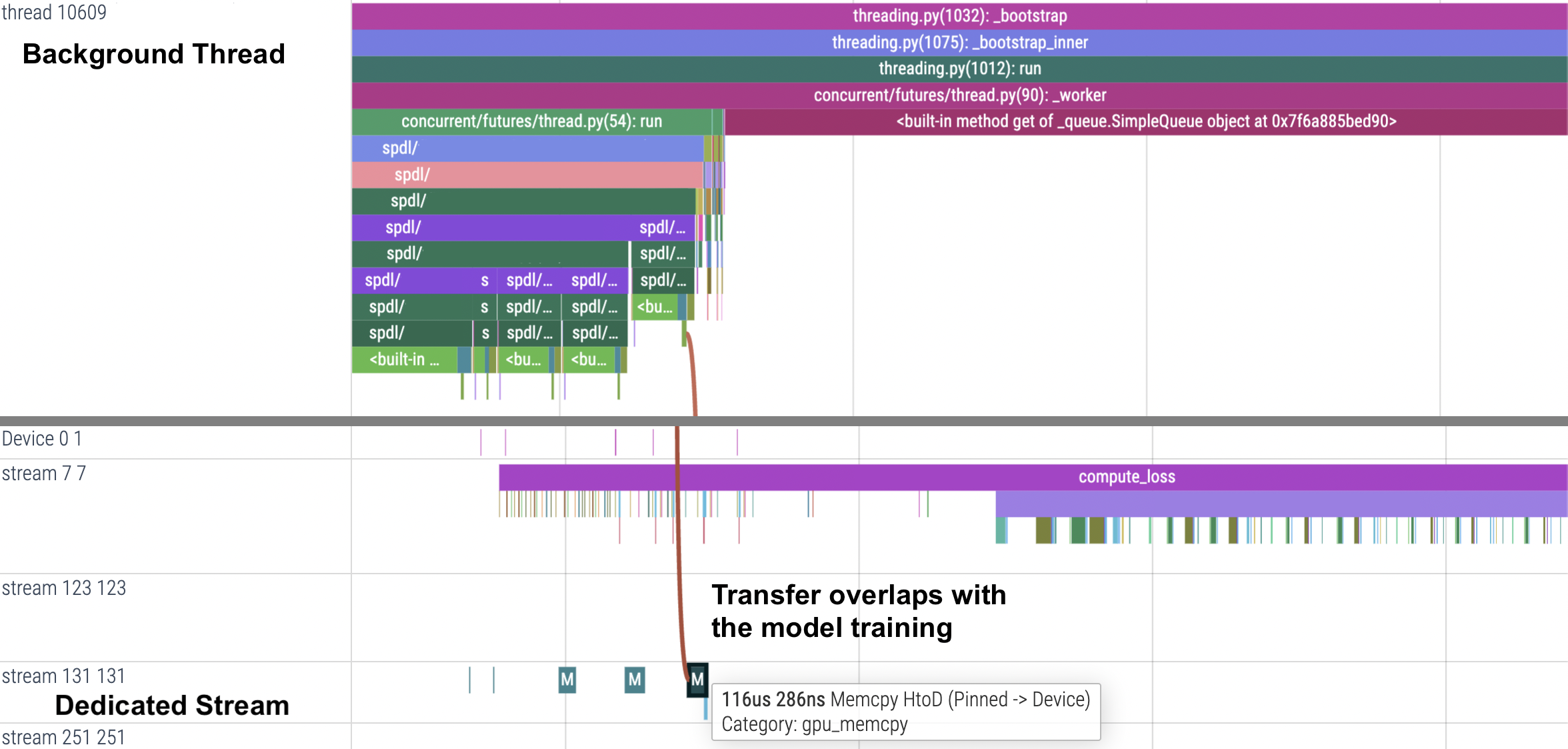
One notable example that meets these conditions is transferring data to the GPU. Due to the hardware constraints, only one data transfer can be performed at a time. To transfer data without interrupting the model training, you need to use a stream object dedicated for the transfer, and you want to keep using the same stream object across multiple function invocations.
To maintain a state, you can either encapsulate it in a callable class instance, or put it in a thread-local storage. The following example shows how to initialize and store a CUDA stream in a thread-local storage.
Note
The following code is now available as spdl.io.transfer_tensor().
import threading
THREAD_LOCAL = threading.local()
def _get_threadlocal_stream(index: int) -> tuple[torch.cuda.Stream, torch.device]:
if not hasattr(THREAD_LOCAL, "stream"):
device = torch.device(f"cuda:{index}")
THREAD_LOCAL.stream = torch.cuda.Stream(device)
THREAD_LOCAL.device = device
return THREAD_LOCAL.stream, THREAD_LOCAL.device
The following code illustrates a way to transfer data using the same dedicated stream across function invocations.
def transfer_data(data: list[Tensor], index: int = 0):
stream, device = _get_threadlocal_stream(index)
with torch.cuda.stream(stream):
data = [
t.obj.pin_memory().to(device, non_blocking=True)
for t in data]
stream.synchronize()
return data
Now we want to run this function in background, but we want to use only one thread,
and keep using the same thread.
For this purpose we create a ThreadPoolExecutor with one thread and pass it to
the pipeline.
transfer_executor = ThreadPoolExecutor(max_workers=1)
pipeline = (
PipelineBuilder()
.add_source(...)
.pipe(...)
.pipe(transfer_data, executor=transfer_executor)
.add_sink(...)
)
This way, the transfer function is always executed in a dedicated thread, so that it keeps using the same CUDA stream.
When tracing this pipeline with PyTorch Profiler, we can see that it is always the one background thread that issues data transfer, and the transfer overlaps with the stream executing the model training.
Multi-processing (stage)¶
What if a function does not release the GIL? If a stage relies on a function that takes a long time to execute (for example, a network utility, or a long-running pure-Python routine) but does not release the GIL, running it on the shared thread pool blocks the other stages. You can instead delegate that single stage to a subprocess.
PipelineBuilder.pipe() takes an optional executor argument. The
default behavior is to use the thread pool shared among all stages. If you pass
an instance of ProcessPoolExecutor, that stage
executes the function in a subprocess, free of the GIL.
executor = ProcessPoolExecutor(max_workers=num_processes)
pipeline = (
PipelineBuilder()
.add_source(src)
.pipe(stage1, executor=executor, concurrency=num_processes)
.pipe(stage2, ...)
.pipe(stage3, ...)
.add_sink(1)
.build()
)
This builds a pipeline like the following, where stage1 runs in the process
pool while stage2 and stage3 stay on the main process’s thread pool.
Note
Multi-processing characteristics:
Each process has its own isolated memory space
No GIL constraints - true parallelism for CPU-bound tasks
Data must be pickled and copied between processes (overhead)
Slower startup due to process creation
Best for CPU-bound tasks that hold the GIL
Note
Along with the function arguments and the return value, the function (callable) itself is serialized and sent to the subprocess, then the result is sent back. Therefore the function, its input argument, and its output value must all be picklable. Plain functions work; closures and class methods cannot be passed.
If you want to bind extra arguments to a function, you can use
functools.partial(). If you want to pass around an object that’s not
picklable by default, you can define the serialization protocol by providing
object.__getstate__() and object.__setstate__().
Tip
If you need to perform one-time initialization in the subprocess, you can use
the initializer and initargs arguments.
The values passed as initializer and initargs must be picklable.
If constructing an object in a process that does not support pickle, then
you can pass constructor arguments instead and store the resulting object
in global scope. See also https://stackoverflow.com/a/68783184/3670924.
Example
def init_resource(*args):
global rsc
rsc = ResourceClass(*args)
def process_with_resource(item):
global rsc
return rsc.process(item)
executor = ProcessPoolExecutor(
max_workers=4,
mp_context=None,
initializer=init_resource,
initargs=(...),
)
pipeline = (
PipelineBuilder()
.add_source()
.pipe(
process_with_resource,
executor=executor,
concurrency=4,
)
.add_sink(3)
.build()
)
The cost of crossing a process boundary¶
Every time a stage is dispatched to a subprocess, its input is pickled and copied into the worker, and the result is pickled and copied back. For a single heavy, GIL-holding stage this overhead is easily worth it. See The Cost of Inter-Process Communication for why this pickle-and-copy is expensive and how it scales with the payload.
The size of what crosses the boundary matters too, since pickling and copying a
large payload is costly and is paid on both sides. PyTorch tensors (and NumPy
arrays) are the exception: their buffers are moved through shared memory and only
a handle is pickled, so transferring them is far cheaper than their size suggests
— even though a fresh shared-memory segment is allocated on each pickling. Prefer
passing a torch.Tensor across the boundary. To send a raw byte string
cheaply, write it to shared memory yourself, or wrap it in a 1-D uint8 tensor
so it rides the same fast path.
To squeeze the last bit of IPC performance,
SharedMemorySegmentPool reuses a pre-allocated pool of
shared-memory segments instead of allocating one per transfer, edging out a plain
tensor. See the shared-memory arena case study and
the benchmark_arena_transport example for the measured numbers.
But if you send several consecutive stages each to a ProcessPoolExecutor, the
data makes a round trip between the main process and a worker at every stage
boundary. Copying data back and forth like this wastes both time and memory.
To keep several stages running together inside the workers without paying a per-stage round trip, mark a region of the pipeline (next section) or run the whole pipeline in a subprocess. These are the building blocks behind the recommended MP and MTP patterns; see Execution Models: MT, MTP, and MP.
Multi-processing (region)¶
Rather than paying a process round trip per stage, you can mark a region of
the pipeline to run together in a worker pool with
to(). Every stage between
.to(ProcessPoolExecutorConfig(...)) and .to(MAIN_PROCESS) runs
as one nested Pipeline inside a pool of worker processes:
from spdl.pipeline.defs import MAIN_PROCESS, ProcessPoolExecutorConfig
pipeline = (
PipelineBuilder()
.add_source(...)
.to(ProcessPoolExecutorConfig(max_workers=4))
.pipe(op1, concurrency=2) # runs in a worker process
.aggregate(batch_size) # runs in a worker process
.pipe(op2, concurrency=3) # runs in a worker process
.to(MAIN_PROCESS) # data returns to the main process
.add_sink(...)
.build(num_threads=...)
)
Because the region’s stages run back-to-back inside one worker, the value handed
from one stage to the next is not copied back to the main process between
them. This removes the inter-stage IPC entirely, and — unlike the per-stage
multi-processing above — those intermediate values do not need to be
picklable; only the region’s inputs and outputs cross the process boundary. Each
stage keeps its own concurrency and its own per-stage performance stats (the
nested pipeline is built with the usual hooks, so the stats are reported from
inside the worker).
Note
A stage’s concurrency applies within each worker process, so the
effective concurrency of a stage across the pool is
concurrency × max_workers. For example, .pipe(op, concurrency=2) in a
region with max_workers=4 runs up to 8 invocations of op at once. Size
each stage’s concurrency together with max_workers to stay within your
CPU budget.
Unlike passing executor= to individual
pipe() calls, a region also carries
aggregate(),
disaggregate(), and
path_variants() stages into the worker,
and gives the worker-pool configuration (worker count, mp_context,
initializer) a single home. A pipeline starts on the main process, so a
region is opened by a .to(ProcessPoolExecutorConfig(...)) and closed by
.to(MAIN_PROCESS); the region must be closed before
add_sink().
Inside a region, generator ops and async ops work as usual, a
continuous source keeps the
worker sub-pipelines warm across epochs, and a region composes with
run_pipeline_in_subprocess(). Every op must be picklable,
since the region config is shipped to the worker. See the
to() reference for the details.
To run a region in subinterpreters (Python 3.14+) instead of subprocesses,
pass a InterpreterPoolExecutorConfig; the region’s ops
must avoid NumPy/PyTorch, which cannot be imported in a subinterpreter.
Note
A region produces results in completion order across its pool workers, so a
stage built with output_order="input" cannot appear inside a region.
Running a pipeline in a subprocess¶
The spdl.pipeline.run_pipeline_in_subprocess() function moves a given
PipelineBuilder configuration to a subprocess, builds and runs the
Pipeline there, and delivers the results to the main process through
an inter-process queue.
Note
How it works:
Subprocess: runs the full pipeline with its own event loop and thread pool.
IPC Queue: results are transferred to the main process via inter-process communication.
Main process: iterates the returned iterable to receive the results.
The following example shows how to use the function.
# Construct a builder and get its config
builder = (
spdl.pipeline.PipelineBuilder()
.add_source(...)
.pipe(...)
...
.add_sink(...)
)
config = builder.get_config()
# Move it to the subprocess, build the Pipeline
iterable = run_pipeline_in_subprocess(config, num_threads=...)
# Iterate - epoch 0
for item in iterable:
...
# Iterate - epoch 1
for item in iterable:
...
Note
Advanced Usage:
Pipelines with Merge: You can run pipelines with sub-pipelines constructed using
Mergeby directly passing thePipelineConfigobject torun_pipeline_in_subprocess. This allows complex pipeline topologies to be executed in a subprocess.Subinterpreter Execution: For Python 3.14 and above, the
run_pipeline_in_subinterpreter()function is also available. It executes the pipeline in a separate interpreter within the same process, providing interpreter-level isolation while being lighter weight than a full subprocess.
Because the result of run_pipeline_in_subprocess is an iterable, you can
build another Pipeline on top of it. See Execution Models: MT, MTP, and MP for
the execution patterns that build on this primitive.