spdl.io.transfer_tensor¶
- transfer_tensor(batch: T, /, *, num_caches: int = 4) T[source]¶
Transfers PyTorch CPU Tensors to CUDA in a dedicated stream.
This function wraps calls to
torch.Tensor.pin_memory()andtorch.Tensor.to(), and execute them in a dedicated CUDA stream.When called in a background thread, the data transfer overlaps with the GPU computation happening in the foreground thread (such as training and inference).
See also
Multi-threading (custom) - An intended way to use this function in
Pipeline.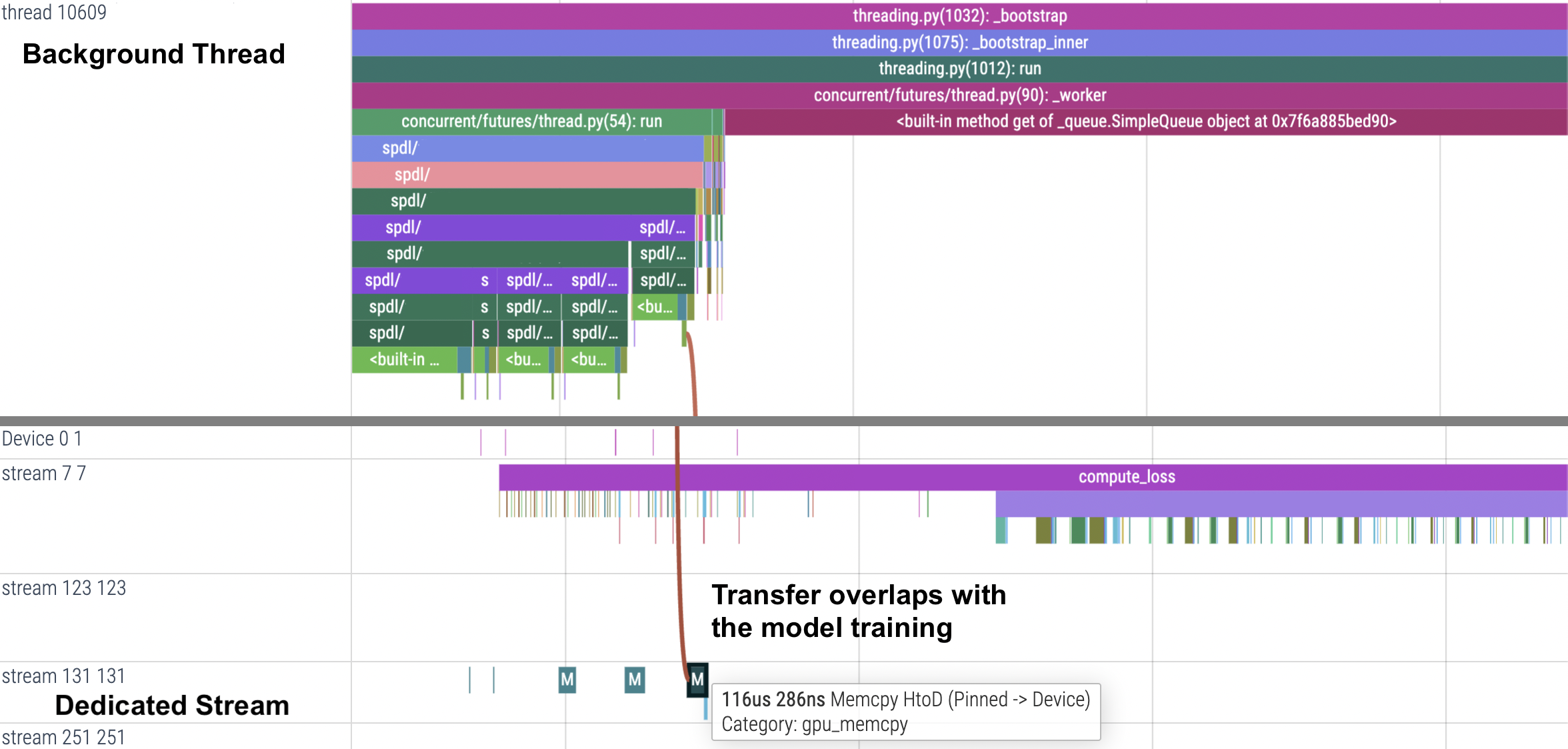
Concretely, it performs the following operations.
If a dedicated CUDA stream local to the calling thread is not found in a thread-local storage, creates and stashes one. (The target device is deetrmined by
"LOCAL_RANK"environment variable.)Activates the CUDA stream.
Traverses the given object recursively, and transfer tensors to GPU. Data are first copied to page-locked memory by calling
pin_memorymethod, then the data is transferred to the GPU in asynchronous manner. (i.e..to(non_blocking=True))Synchronizes the stream, to ensure that all the data transfers are completed.
- Parameters:
batch – A
Torch.Tensoror a composition of tensors with container types such aslist,tuple,dictanddataclass.num_caches –
Number of batch caches to maintain the reference to. This parameter helps mitigate race conditions when using multi-threading with multiple CUDA streams.
See PyTorch CUDA Race Condition in Multi-threading for details on the rationale behind this parameter.
- Returns:
An object of the same type as the input, but the PyTorch tensors are transferred to CUDA device.