Gaia2 and Leaderboard Submission¶
This tutorial guides you through the complete process of evaluating your AI agent on the Gaia2 benchmark and contributing to the research leaderboard. Gaia2 is a comprehensive benchmark that evaluates general agent capabilities across multiple dimensions including execution, search, adaptability, temporal reasoning, ambiguity handling, and multi-agent collaboration.
About Gaia2¶
What is Gaia2?¶
Gaia2 significantly expands the scope of agent evaluation beyond the original GAIA benchmark’s web-based search focus. While GAIA proved valuable for evaluating web browsing and deep search capabilities, Gaia2 operates within a comprehensive simulated environment that tests the full breadth of skills required for practical AI assistants.
Gaia2 addresses fundamental limitations of existing benchmarks by introducing several novel evaluation dimensions:
Expanded Action Space: Rich set of APIs and tools across multiple applications, enabling complex multi-app workflows
Dynamic Environment Events: Time-dependent events that modify the world state while agents work
Temporal Reasoning: Explicit time constraints and scheduling requirements
Multi-Agent Collaboration: Agents must collaborate with other agents representing applications
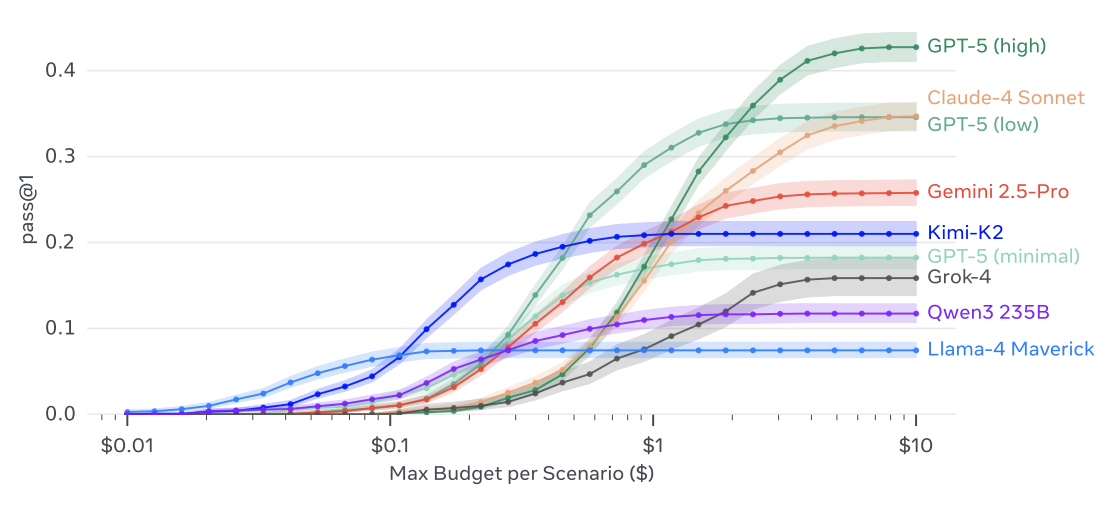
Gaia2 budget scaling curves for popular models. The budget scaling curves show the trade-off between performance and computational cost.¶
For comprehensive information about Gaia2, refer to:
Research Paper: ARE: Scaling Up Agent Environments and Evaluations - Read the research paper detailing the Gaia2 benchmark and evaluation methodology
Blog Post: Gaia2 on Hugging Face - Learn more about Gaia2 on the Hugging Face blog
Benchmark Structure¶
Gaia2 comprises 800 carefully crafted scenarios designed within pre-populated ARE environments:
10 Distinct Universes: A Universe is a simulated user environment (with specific data, mails, events, objectives). 10 universes provide diverse backgrounds
11 Core Applications: The base AgentUserInterface to interact with the agent, several messaging apps (MessagingApp, ChatsApp, EmailClient), and utilities (Calendar, Contacts, RentAFlat, Shopping, Cab, City, and FileSystem)
800 Dynamic Scenarios: Each scenario represents a time-based simulation with events, tasks, and validation criteria
Gaia2-mini is a representative subset of 160 scenarios from Gaia2. It is designed to provide a comprehensive evaluation of the core agent capabilities, while maintaining a manageable size for benchmarking and research purposes. The 160 scenarios are evenly distributed across the 5 core capabilities: execution, search, adaptability, time, ambiguity,
Evaluated Capabilities¶
Gaia2 evaluates seven core agent capabilities with equal weight in the final score:
Core Capabilities (Standard evaluation on full datasets)
- Execution (160 scenarios)
Multiple state-changing operations requiring planning and correct sequencing
Example: “Update all my contacts aged 24 or younger to be one year older than they are currently.”
- Search (160 scenarios)
Multi-step information gathering and combination from different sources
Example: “Which city do most of my friends live in? I consider any contact who I have at least one 1-on-1 conversation with on ChatsApp a friend.”
- Adaptability (160 scenarios)
Dynamic adaptation to environmental changes and consequences of agent actions
Example: “Meet my friend to view a property. If she replies to suggest another property or time, please replace it with her suggestion.”
- Time (160 scenarios)
Temporal reasoning with precise timing and scheduling constraints
Example: “Send ChatsApp messages to colleagues. If after 3 minutes there is no response, order a default cab.”
- Ambiguity (160 scenarios)
Recognition of impossible, contradictory, or inherently ambiguous tasks requiring clarification
Example: “Schedule a 1h Yoga event each day at 6:00 PM from October 16-21, 2024. Ask me in case there are conflicts.”
Augmentation Capabilities (Evaluated on Gaia2-mini datasets)
- Agent2Agent (160 scenarios)
Collaboration with other agents representing applications through communication rather than direct API access. Evaluated on the Gaia2-mini subset.
- Noise (160 scenarios)
Robustness to environment instability, API changes, and random failures. Evaluated on the Gaia2-mini subset.
Dataset Structure:
Validation set: 800 standard scenarios (5×160 per capability) + 320 augmentation scenarios (2×160 mini)
Final scoring: Each of the 7 capabilities receives equal weight, with global scores reported for test sets to address variance from smaller sample sizes.
Evaluation Process Overview¶
The Gaia2 evaluation process follows these key steps:
Development Phase: Use validation split with oracle events for model improvement
Leaderboard Submission: Run validation split to generate traces for leaderboard submission
Submission: Upload traces and JSON report to the leaderboard
Important Notes:
The test set is entirely private and reserved for internal validation by Meta/Hugging Face
All leaderboard submissions are made using the validation set on a voluntary, non-controlled basis
Researchers must respect the benchmark integrity and avoid using validation data for training
Phase 1: Setup¶
Setting Up Your Environment¶
First, ensure you have uvx installed (comes with uv):
# Install uv (which includes uvx)
curl -LsSf https://astral.sh/uv/install.sh | sh
Then, make sure to login to huggingface to be able to download and upload datasets (Hugging Face CLI login guide):
huggingface-cli login
Note
We recommend using uvx –from meta-agents-research-environments to run the are-* commands without installing the package locally. If you want to dig deeper into the library or develop custom scenarios, you can install it locally with pip install meta-agents-research-environments.
Configure your model provider. Gaia2 supports any model through LiteLLM integration:
For Local Models
use –provider local.
For API-Based Models
# Llama API
export LLAMA_API_KEY="your-api-key"
# OpenAI
export OPENAI_API_KEY="your-api-key"
# Anthropic
export ANTHROPIC_API_KEY="your-api-key"
For comprehensive model configuration options, see Foundations and the LiteLLM documentation.
Phase 2: Validation Set Evaluation for Leaderboard Submission¶
The Gaia2 leaderboard uses the validation set for all submissions. The test set remains entirely private and is reserved for internal validation by Meta/Hugging Face.
Gaia2 Submission Command¶
Use the dedicated gaia2-run command for complete leaderboard evaluation. This command automatically handles all required configurations and phases:
Validation Mode (Recommended First Step)
Before running the full validation evaluation, test your setup using a small subset; the mini partition provides a representative sample of all capabilities:
# Validate your configuration first
uvx --from meta-agents-research-environments are-benchmark gaia2-run --hf meta-agents-research-environments/gaia2 \
--config mini \
--model your-model --provider your-provider \
--output_dir ./gaia2_validation_results
This validation run will:
Test all three evaluation phases on a small subset
Verify your model configuration works correctly
Generate an evaluation report to assess readiness for the full validation run
Identify any configuration issues before the full validation run
Full Validation Evaluation for Leaderboard
Once your setup is validated, run the complete validation evaluation for leaderboard submission:
# Complete Gaia2 leaderboard submission on validation set
uvx --from meta-agents-research-environments are-benchmark gaia2-run --hf-dataset meta-agents-research-environments/gaia2 \
--model your-model --provider your-provider \
--output_dir ./gaia2_submission_results \
--hf_upload your-org/gaia2-submission-traces
The gaia2-run command automatically:
Runs all capability configs: execution, search, adaptability, time, ambiguity
Executes three evaluation phases:
Standard runs: Base agent performance across all capabilities
Agent2Agent runs: Multi-agent collaboration scenarios (
--a2a_app_prop 1)Noise runs: Robustness evaluation with environment perturbations
Forces 3 runs per scenario: For proper variance analysis required by the leaderboard
Generates validation reports: Comprehensive performance summaries
Handles Hugging Face uploads: Consolidated traces ready for submission
Running Validation Scenarios Manually¶
The validation split contains oracle events that enable judge-based evaluation for immediate feedback, you can run this with the run/judge commands of the are-benchmark tool:
# Run Gaia2-mini validation (160 scenarios)
uvx --from meta-agents-research-environments are-benchmark run --hf-dataset meta-agents-research-environments/gaia2 \
--hf-split validation --hf-config mini \
--model your-model --provider your-provider \
--output_dir ./validation_results
# Run specific capability validation
uvx --from meta-agents-research-environments are-benchmark run --hf-dataset meta-agents-research-environments/gaia2 \
--hf-split validation --hf-config execution \
--model your-model --provider your-provider \
--limit 20
Available Configurations:
mini: Gaia2-mini (160 scenarios across all capabilities)execution: Execution scenarios onlysearch: Search scenarios onlyadaptability: Adaptability scenarios onlytime: Time scenarios onlyambiguity: Ambiguity scenarios only
You can enable agent to agent and noisy scenarios with --a2a_app_prop 1.0 and --noise respectively.
Validating Results with Judge System¶
The judge system automatically runs during the run command to provide real-time validation. However, you can also run offline validation using the judge command on pre-recorded traces.
# Judge system runs automatically during run (online validation)
uvx --from meta-agents-research-environments are-benchmark run --hf-dataset meta-agents-research-environments/gaia2 \
--hf-split validation --hf-config mini \
--model your-model --provider your-provider \
--output_dir ./validation_results
Note
Online vs Offline Validation: The run command performs online validation (real-time during execution), while the judge command performs offline validation (against pre-recorded traces). In most cases, you only need the run command as it includes validation automatically.
For detailed information about judge system capabilities, see Judge System for Scenario Validation.
Phase 3: Leaderboard Submission¶
Preparing Your Submission¶
Using the gaia2-run command, you can automatically generate a submission-ready dataset on Hugging Face for the leaderboard by specifying –hf_upload cli argument. This dataset contains all traces generated during the test evaluation, ready for submission. You can upload it as a private dataset if you want.
A basic README will be created for your dataset, you can then update it in the dataset repository with more details if you want.
Submission Process¶
Submit your results to the Gaia2 leaderboard:
Access Submission Form: Visit the Gaia2 Leaderboard <https://huggingface.co/spaces/meta-agents-research-environments/leaderboard>
Login to Hugging Face: Use your Hugging Face account to connect
Provide Dataset Information: - Hugging Face dataset name containing your traces and JSON report - Model name and provider information - Any special configuration details
Submit for Evaluation: Your traces and results will be processed by the leaderboard system
Submission Guidelines
All submissions are made on a voluntary, non-controlled basis by researchers or organizations (Hugging Face/Meta). To maintain benchmark integrity:
Submit accurate results: Ensure your JSON report accurately reflects your model’s performance
Respect benchmark ethics: Do not use validation data for training or attempt to game the system
Leaderboard Updates¶
Once submitted, the leaderboard system will:
Download Your Dataset: Access your Hugging Face dataset containing traces and JSON report
Validate Submission: Verify the completeness and format of your submission
Process Results: Extract performance metrics from your JSON report
Update Leaderboard: Add your results to the public leaderboard
Leaderboard Metrics¶
Gaia2 evaluation provides comprehensive metrics with detailed statistical analysis, see Benchmarking with Meta Agents Research Environments for more details.
Advanced Usage¶
Multi-Run Analysis¶
Run multiple evaluations to assess consistency:
# Run each scenario 5 times for variance analysis
uvx --from meta-agents-research-environments are-benchmark run --hf meta-agents-research-environments/gaia2 \
--hf-split test --config mini \
--model your-model --model_provider your-provider \
--num_runs 5 \
--output_dir ./variance_analysis
Capability-Specific Analysis¶
Focus evaluation on specific capabilities:
# Deep dive into temporal reasoning
uvx --from meta-agents-research-environments are-benchmark run --hf meta-agents-research-environments/gaia2 \
--hf-split validation --config time \
--model your-model --model_provider your-provider \
--output_dir ./time_analysis
Troubleshooting¶
Common Issues¶
- Authentication Errors
Verify API keys are correctly set for your model provider
Check Hugging Face credentials for dataset upload
- Scenario Timeout Issues
Increase
--scenario_timeoutfor complex scenariosReduce
--max_concurrent_scenariosto avoid resource contention
- Trace Upload Failures
Verify Hugging Face dataset permissions
Check network connectivity and dataset size limits
- Model Connection Issues
Test model connectivity with simple queries first
Check endpoint URLs and authentication for local deployments
Getting Help¶
For additional support:
Documentation: Review Benchmarking with Meta Agents Research Environments and Judge System for Scenario Validation
Model Configuration: See Foundations for LLM setup details
Technical Issues: Check error logs in your output directory
Community: Engage with other researchers using Gaia2