Universes¶
Universes: Generating Synthetic Environment State Data at Scale¶
The Agents Research Environments launches with an initial environment implementation: the Mobile Device (MD) environment. This is our first environment, to show the platform’s capabilities, and the system was built to support any other environments (e.g. personal workspaces, code repositories, finance terminals, gaming environments, etc.) Within our initial Mobile Device environment, we introduce the concept of “universes,” which represent distinct flavors or instantiations of the base environment. A universe is a complete version of the simulated world viewed from a specific user’s perspective, populated with synthetic realistic data, a subset of apps from the environment, and contextual information that reflects authentic usage patterns.
Design Philosophy and Approach Evolution
Task-first Approach: The universe concept emerged from a fundamental shift in our development methodology. The traditional approach followed a linear progression from scenario conception to universe creation, requiring extensive manual effort to construct each simulated environment. This process proved time-intensive and often resulted in sparse, unrealistic environments that poorly reflected real-world complexity.
Data-first Approach: Our revised approach inverts this relationship, beginning with richly populated, realistic universes that subsequently inspire scenario development. Well-populated universes establish environmental complexity comparable to actual mobile devices, complete with realistic application content including message histories, email threads, calendar events, and other authentic digital artifacts. This comprehensive environmental foundation enables researchers to easily identify compelling use cases and challenges that require agents to perform meaningful, realistic tasks.
By enabling researchers to browse and explore realistic, fully-populated environments, the universe approach facilitates organic scenario discovery that requires minimal environmental modification. This methodology creates a natural hierarchy where the platform contains multiple environments, each environment supports multiple universes, and each universe can host multiple scenarios, providing scalable content generation for diverse research applications.
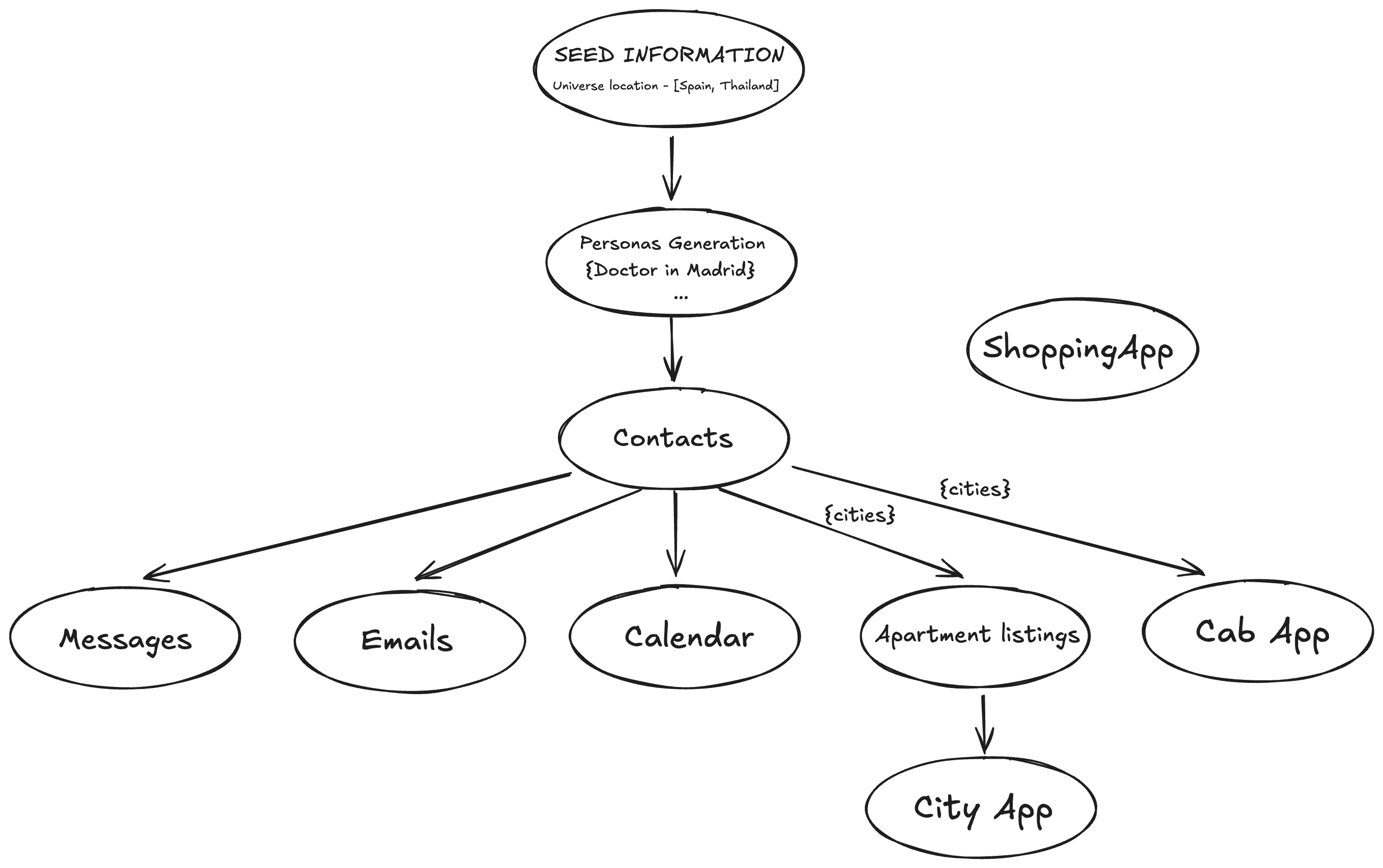
Universe Generation Pipeline
Applications within universes require realistic data population that aligns with the user’s personality and maintains coherence across the entire environment. We developed a multi-stage synthetic data generation pipeline (using Llama-3.1-70B) that ensures both authenticity and internal consistency:
Persona Foundation: Pipeline begins with a seed persona from PersonaHub
Persona Augmentation: Multiple characteristics are added to provide depth and behavioral nuance
Contact Generation: Coherent contacts list created reflecting realistic relationship patterns
Information Propagation: Persona and contact details distributed to application-specific data generation scripts to maintain environment-wide coherence
Temporal Generation: Time-dependent apps like Calendar generate content iteratively (week-by-week) to construct continuous, coherent event timelines
Independent Population: Some apps use publicly available datasets (e.g., Amazon products for Shopping App) when persona integration isn’t required
This approach ensures that scenarios emerge naturally from well-populated, realistic universes rather than requiring manual environment construction for each use case. Below a high-level diagram of the universe generation pipeline.
Next Steps
Keep reading the Foundations guide to learn more about Scenarios.