Scenarios¶
Scenarios: Bringing together every pieces¶
In the Agents Research Environments, scenarios represent dynamic, time-based simulations that test AI assistants in realistic, evolving environments. To understand scenarios, we first need to distinguish between two key concepts:
Universe: represents a static initial state containing all the environmental setup and baseline data.
Scenario: is a dynamic simulation that evolves over time, beginning from a universe’s state at t=0.
This distinction is reflected in our implementation: the Gaia2 benchmark lives in the Mobile Device Environment, which contains approximately 20 universes, across which roughly 800 scenarios are distributed.
Note that a Universe is optional, some tasks could start from an empty environment, i.e. create a codebase from scratch.
Anatomy of a Scenario¶
Each scenario in our simulated environment consists of four core components that work together to create a comprehensive testing environment.
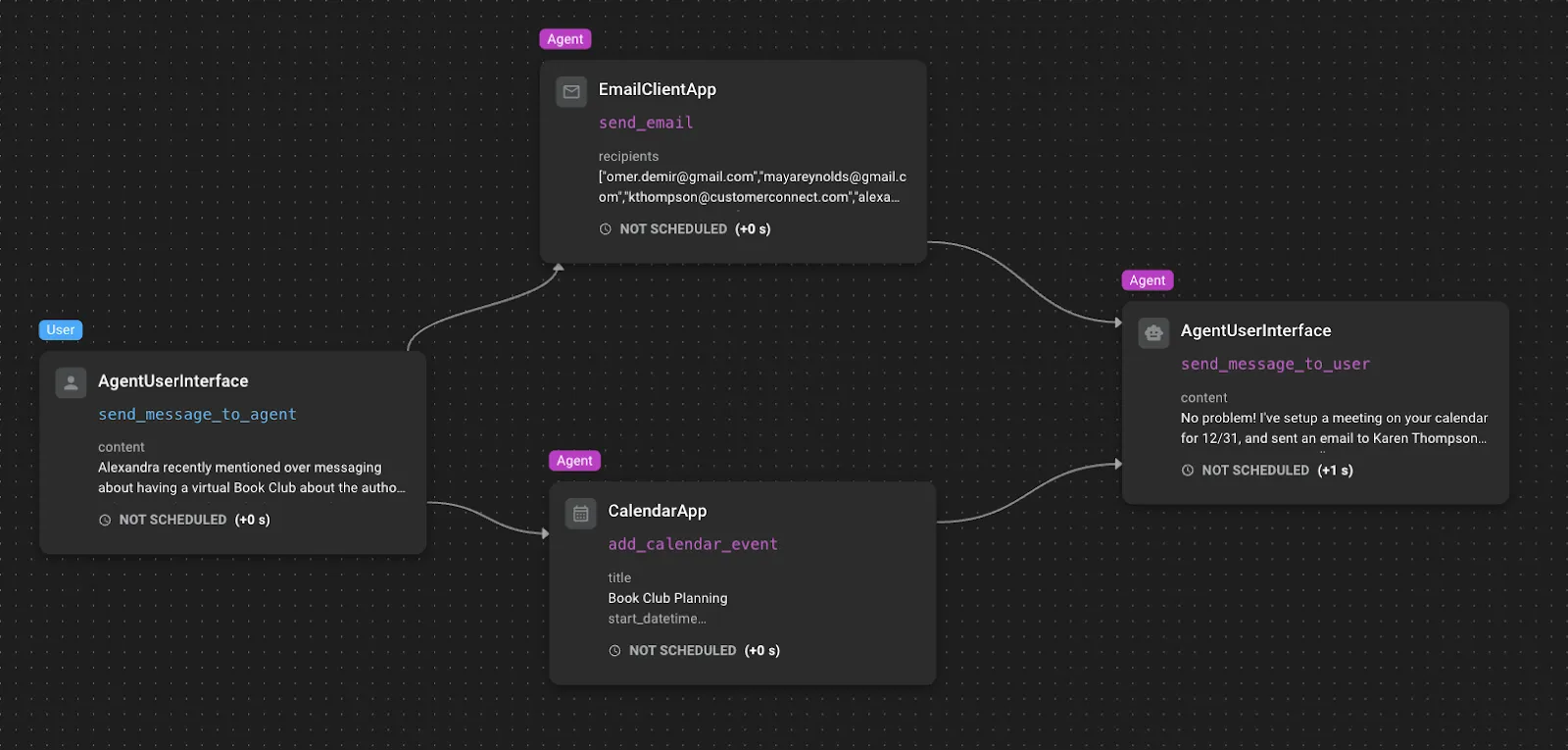
The universe foundation provides a realistic environment populated with various applications such as messaging, email, and weather apps, along with their initial data states. This foundation serves as the starting context for the simulation.
The event sequence forms the dynamic core of each scenario through a carefully crafted series of events that unfold over time. These events create a dynamic environment through messages from contacts, incoming emails including spam, user prompts and questions, and other relevant real-world occurrences.
Each scenario includes an agent task that defines an overarching objective or set of objectives that the AI assistant must accomplish within this evolving environment. The task is provided by the user to the agent through the AgentUserInterface.
Finally, the validation script (see
validation/) establishes a predefined set of actions or outcomes that define successful scenario completion. The validation can be done using a combination of different validation techniques: state-based, using LLM-as-a-Judge, etc… In the platform, we encourage tasks designers to evaluate a model based on its write actions, i.e. those that change the environment, rather than only state. (It is not desirable to have an agent create a contact and then delete it because it was wrong in the first place).
Evaluation Goals¶
Scenarios are designed to evaluate an AI assistant’s ability to maintain and use context over extended time periods, connect disparate pieces of information across multiple interactions, and prioritize important tasks while managing distractions. Additionally, they assess the Agent’s capacity to take proactive actions when situationally appropriate and communicate effectively with users throughout the process.
By subjecting AI assistants to these multi-faceted scenarios, we can assess their performance on complex, long-term tasks that closely mirror real-world challenges, providing insights into their readiness for deployment in practical applications.
Example: Scenario Distribution in Gaia2
Gaia2 includes 5 splits of 160 tasks each, covering the following agent abilities:
Ability |
Description |
Example |
Explanation |
|---|---|---|---|
Execution |
Tasks that require potentially many write actions, i.e. actions that modify the state of the world |
Update all my contacts aged 24 or younger to be one year older than they are currently. |
Updating contacts will require to update the Contacts App data, modifying the state of the world. |
Search |
Tasks that require potentially many read actions, i.e. similar to GAIA / Deep Research, but with a simulated environment instead of the real Web |
Which city do most of my friends live in? I consider any contact who I have at least one 1-on-1 conversation with on WhatsApp a friend. In case of a tie, return the first city alphabetically. |
The agent only needs to browse the relevant apps, without needing to modify any state. |
Ambiguity |
Tasks requiring adaptation to changes in the environment to be completed successfully |
I have to meet my friend Kaida Schönberger to view a property with her […] If she replies to suggest another property or time, please replace it with the listing she actually wants and reschedule at the time that works for her. |
Agents will need to adapt what was done according to the user’s friend’s reply. |
Time |
Tasks (repeated or not) to be completed in due time |
If any new properties are listed in the next 50 minutes, please save them so I can review them later. After saving each property, send me an email with the subject as the property name and the property details as the email content. |
Agent needs to check time to only list properties within the next 50mins (not after), and then contact the user. |
Adaptability |
Ambiguous tasks requiring user feedback or confirmation, whether because they are high-stakes or not possible under the agent’s affordances |
Schedule a 1h Yoga event each day at 6:00 PM from October 16, 2024 to October 21, 2024. Ask me in case there are conflicts |
While this task seems simple at first glance, current models struggle to see contradictions/multiple valid answers and tend to blindly execute the first seemingly valid interpretation of the task |
Additionally, we created Gaia2-mini, a subset of 160 scenarios of Gaia2, that can be used for cheaper evaluation and fast iteration.
Scenario augmentation and Gaia2 extensions
Scenarios ground truth are invariant to many changes in the environment, allowing to easily extend Gaia2 without new annotations:
Agent2Agent: some apps of the environment can be replaced by agents representing them, with the main agent being able to communicate with the app agent, but not use their app tools. Agents now have to collaborate to solve the task. For each scenario of Gaia2-mini, we turn 70% of the apps into subagents that use the same agent being evaluated, since good agent2agent scores require being both good as “main” agent and as “sub” agent.
Noise: finally, we test robustness of the agents to noisy environments, applying to each Gaia2-mini scenarios the following augmentations of the environment:
Tool augmentations: App tools can have their signature / description changed, and receive random failure probabilities.
Environment events: While working, the Environment might evolve (e.g. as the user receives new emails or new products become available for shopping), sometimes requiring the agent to adapt. This augmentation controls the degree to which the environment changes while the agent is working, potentially distracting it.
Gaia2 is the perfect example of an evaluation that leverages most of the platform’s abstractions and potential. While the execution and search tasks remain fairly “simple”, they offer evaluation of tasks grounded in the user’s daily life. The three other subsets are much more representative of the new axes to evaluate agents, dealing with uncertainty, time constraints, context-aware tasks and dynamic user needs.
Finally, we highlight that the platform offers abstractions that allow us to integrate other agentic benchmarks in new environments. We have successfully re-implemented τ-bench and BFCL-v3 with minor friction and no abstractions modifications.
How to Verify an Agent Trajectory? Hands-on with the Verifier¶
Oracle Actions represent a set of tool calls that define a valid trajectory of write actions necessary to solve a task. These actions focus exclusively on write actions, as read actions are not considered part of the “gold” trajectory due to the multiple possible paths available to access the same information.
Write actions are critical because they directly alter the environment’s state. Read actions, conversely, are for information gathering and do not affect the environment’s state.
Oracle actions serve two primary purposes in our framework. First, they enable verification that tasks are feasible by ensuring that all required tool and scenarios function correctly without broken dependencies. Second, they provide a validation mechanism for the Gaia2 benchmark scenarios.
Principle The core principle of the verifier is to align each oracle action with a corresponding agent write action. This process is complicated by the fact that oracle actions are structured within an oracle graph, whereas agent actions are simply ordered chronologically based on their execution time within a trajectory. Consequently, the verifier must also confirm that the agent adheres to the dependencies outlined in the oracle graph. To achieve this, upon finding a match, the verifier validates causality by confirming that all parent actions of the oracle action have been matched with preceding agent actions.
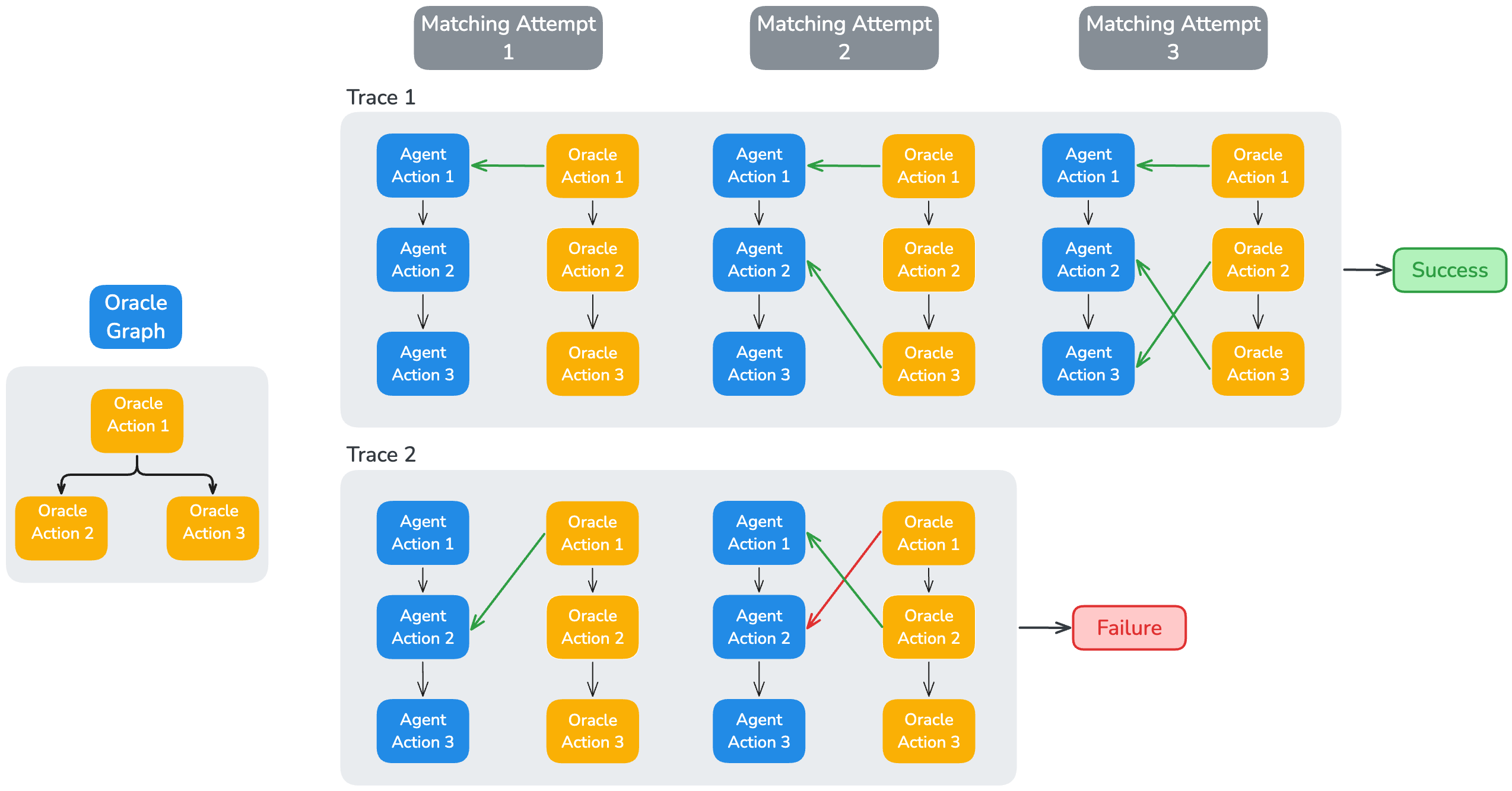
Matching Oracle Action with Agent Action
To match an agent action with an oracle action, we utilize a tool verifier that leverages both hard tool checks and soft tool checks.
Hard Tool Checks: These checks compare the arguments of a tool call between an agent action and an oracle action using scripted validations. For example, when replying to an email, the verifier ensures that the
email_idis identical in both actions. Similarly, when sending an email, it verifies that the unordered list of recipients matches exactly.Soft Tool Checks: These checks compare arguments that require more flexible evaluation. To perform a soft check, a large language model is prompted with the user-provided task as context, along with the arguments from both the agent action and the oracle action. The large language model then determines if the actions are equivalent according to tool-specific guidelines.
Scenario Creation Process: Code vs UI¶
Scenarios can be created from the UI, by using the same validation methods as Gaia2 with Oracle Events: (see UI reference doc). For instance Gaia2 was solely created using the UI to minimize the friction with annotators and make the annotation environment grounded in the uses cases.
Scenarios can be created from code, which is much more flexible and allows any kind of validation. Synthetic data is largely created via code scenarios, where it requires minimal effort to implement template scenarios with many variants and verifiable success.
Next Steps
Check the technical details of Events in Scenarios API.
You have learned about the foundations and how we came up with an initial environment. You can now start interacting with our codebase by following the Tutorials.