Nevergrad - A gradient-free optimization platform

This documentation is a work in progress, feel free to help us update/improve/restucture it!
Quick start
nevergrad is a Python 3.6+ library. It can be installed with:
pip install nevergrad
You can find other installation options (including for Windows users) in the Getting started section.
Feel free to join Nevergrad users Facebook group.
Minimizing a function using an optimizer (here NgIohTuned, our adaptative optimization algorithm) can be easily run with:
import nevergrad as ng
def square(x):
return sum((x - 0.5) ** 2)
# optimization on x as an array of shape (2,)
optimizer = ng.optimizers.NGOpt(parametrization=2, budget=100)
recommendation = optimizer.minimize(square) # best value
print(recommendation.value)
# >>> [0.49999998 0.50000004]
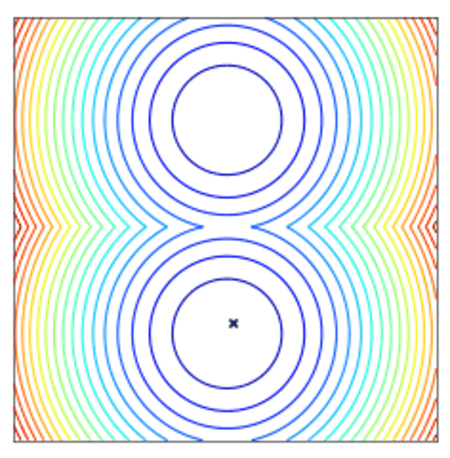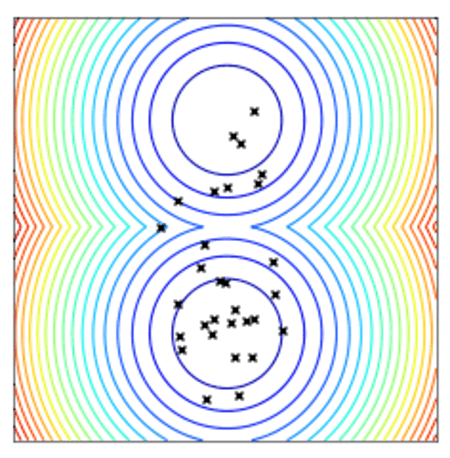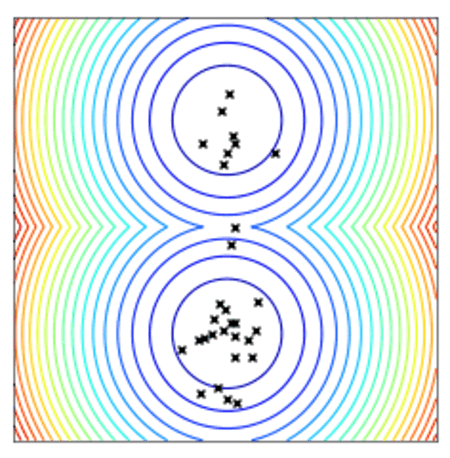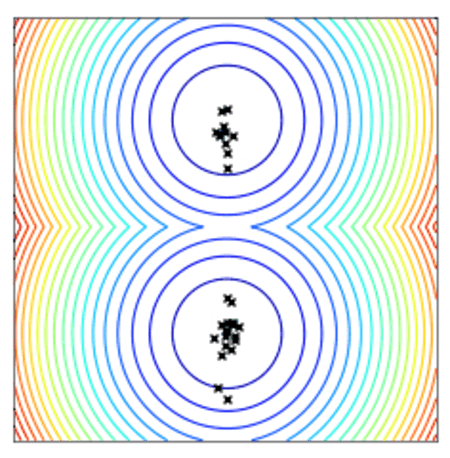
Convergence of a population of points to the minima with two-points DE.
nevergrad can also support bounded continuous variables as well as discrete variables, and mixture of those.
To do this, one can specify the input space:
import nevergrad as ng
def fake_training(learning_rate: float, batch_size: int, architecture: str) -> float:
# optimal for learning_rate=0.2, batch_size=4, architecture="conv"
return (learning_rate - 0.2) ** 2 + (batch_size - 4) ** 2 + (0 if architecture == "conv" else 10)
# Instrumentation class is used for functions with multiple inputs
# (positional and/or keywords)
parametrization = ng.p.Instrumentation(
# a log-distributed scalar between 0.001 and 1.0
learning_rate=ng.p.Log(lower=0.001, upper=1.0),
# an integer from 1 to 12
batch_size=ng.p.Scalar(lower=1, upper=12).set_integer_casting(),
# either "conv" or "fc"
architecture=ng.p.Choice(["conv", "fc"]),
)
optimizer = ng.optimizers.NGOpt(parametrization=parametrization, budget=100)
recommendation = optimizer.minimize(fake_training)
print(recommendation.kwargs) # shows the recommended keyword arguments of the function
# >>> {'learning_rate': 0.1998, 'batch_size': 4, 'architecture': 'conv'}
Learn more about parametrization in the Parametrization section!
Contents
- Getting started
- How to perform optimization
- Basic example
- Using several workers
- Ask and tell interface
- Choosing an optimizer
- Telling non-asked points, or suggesting points
- Adding callbacks
- Optimization with constraints
- Optimizing machine learning hyperparameters
- Example with permutation
- Example of chaining, or inoculation, or initialization of an evolutionary algorithm
- Multiobjective minimization with Nevergrad
- Reproducibility
- Parametrizing your optimization
- Examples - Nevergrad for machine learning
- Optimizers API Reference
- Parametrization API reference
- Running algorithm benchmarks
- Examples - Nevergrad for R
- Examples of benchmarks
- Examples - Working with Pyomo model
- Installation and configuration on Windows
- Contributing to Nevergrad
- Open Optimization Competition 2020
Citing
@misc{nevergrad,
author = {J. Rapin and O. Teytaud},
title = {{Nevergrad - A gradient-free optimization platform}},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://GitHub.com/FacebookResearch/Nevergrad}},
}
License
nevergrad is released under the MIT license. See LICENSE for additional details about it, as well as our Terms of Use and Privacy Policy.
Copyright © Meta Platforms, Inc.