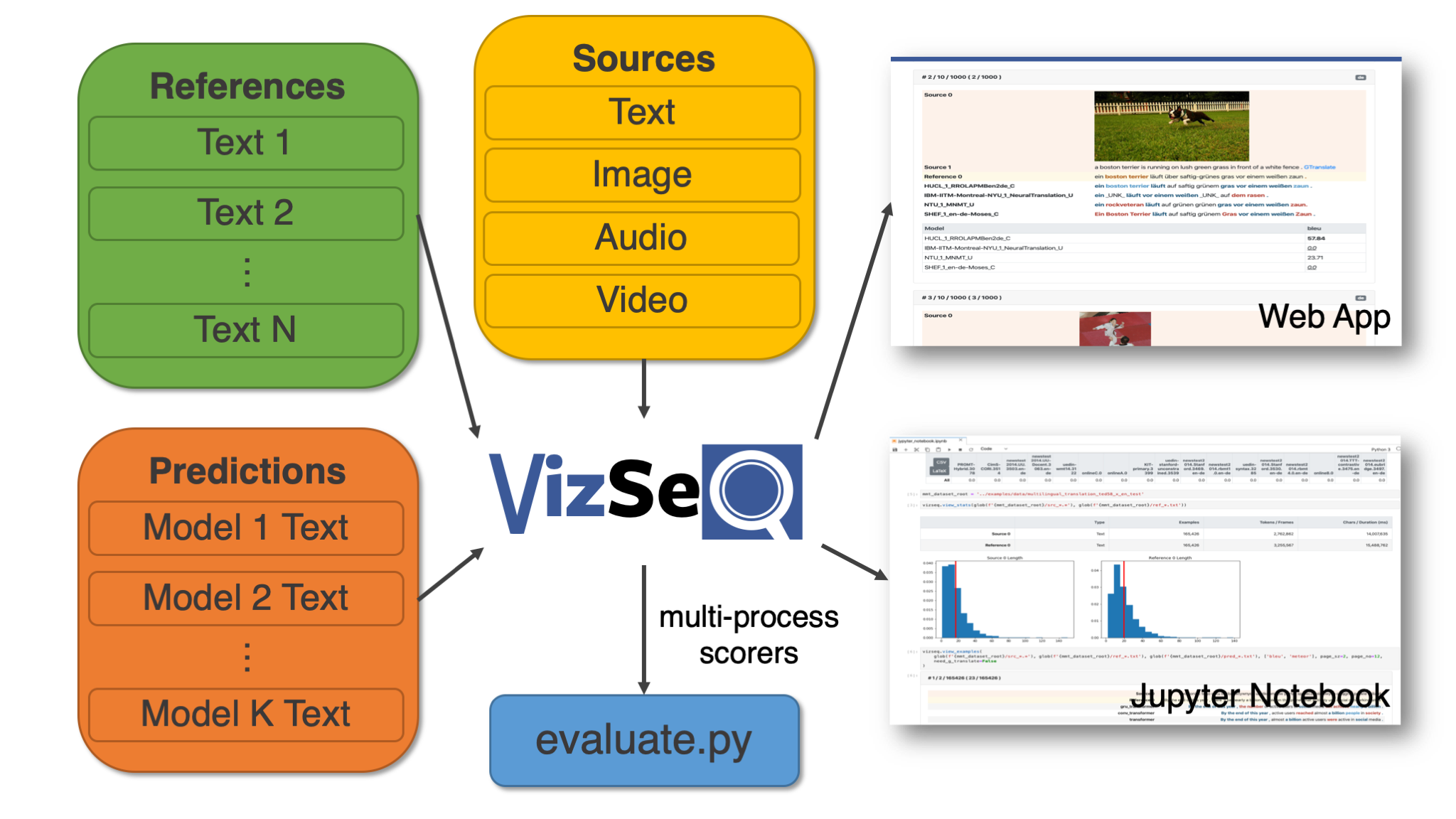
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation and video description. It takes multi-modal sources, text references as well as text predictions as inputs, and analyzes them visually in Jupyter Notebook or a built-in Web App (the former has Fairseq integration). VizSeq also provides a collection of multi-process scorers as a normal Python package.
Please also see our paper for more details. To install VizSeq, check out the instructions here.
Task Coverage
VizSeq accepts various source types, including text, image, audio, video or any combination of them. This covers a wide range of text generation tasks, examples of which are listed below:
| Source | Example Tasks |
|---|---|
| Text | Machine translation, text summarization, dialog generation, grammatical error correction, open-domain question answering |
| Image | Image captioning, image question answering, optical character recognition |
| Audio | Speech recognition, speech translation |
| Video | Video description |
| Multimodal | Multimodal machine translation |
Metric Coverage
Accelerated with multi-processing/multi-threading.
| Type | Metrics |
|---|---|
| N-gram-based | BLEU (Papineni et al., 2002), NIST (Doddington, 2002), METEOR (Banerjee et al., 2005), TER (Snover et al., 2006), RIBES (Isozaki et al., 2010), chrF (Popović et al., 2015), GLEU (Wu et al., 2016), ROUGE (Lin, 2004), CIDEr (Vedantam et al., 2015), WER |
| Embedding-based | LASER (Artetxe and Schwenk, 2018), BERTScore (Zhang et al., 2019) |
License
VizSeq is licensed under MIT.