Example Data
To get the data for the following examples:
$ git clone https://github.com/facebookresearch/vizseq$ cd vizseq$ bash get_example_data.sh
The data will be available in examples/data.
Data Sources
VizSeq accepts data from various types of sources: plain text file paths, ZIP file paths and Python dictionaries. (See also the data inputs section for more details.)
Here is an example for plain text file paths as inputs:
from glob import globroot = 'examples/data/translation_wmt14_en_de_test'src, ref, hypo = glob(f'{root}/src_*.txt'), glob(f'{root}/ref_*.txt'), glob(f'{root}/pred_*.txt')
An example for Python dictionaries as inputs:
from typing import List, Dictimport os.path as opfrom glob import globdef reader(paths: List[str]) -> Dict[str, List[str]]:data = {}for path in paths:name = str(op.splitext(op.basename(path))[0]).split('_', 1)[1]with open(path) as f:data[name] = [l.strip() for l in f]return dataroot = 'examples/data/translation_wmt14_en_de_test'src = reader(glob(f'{root}/src_*.txt'))ref = reader(glob(f'{root}/ref_*.txt'))hypo = reader(glob(f'{root}/pred_*.txt'))
Viewing Examples and Statistics
Please see the Jupyter Notebook APIs section for full references.
First, load the vizseq package:
import vizseq
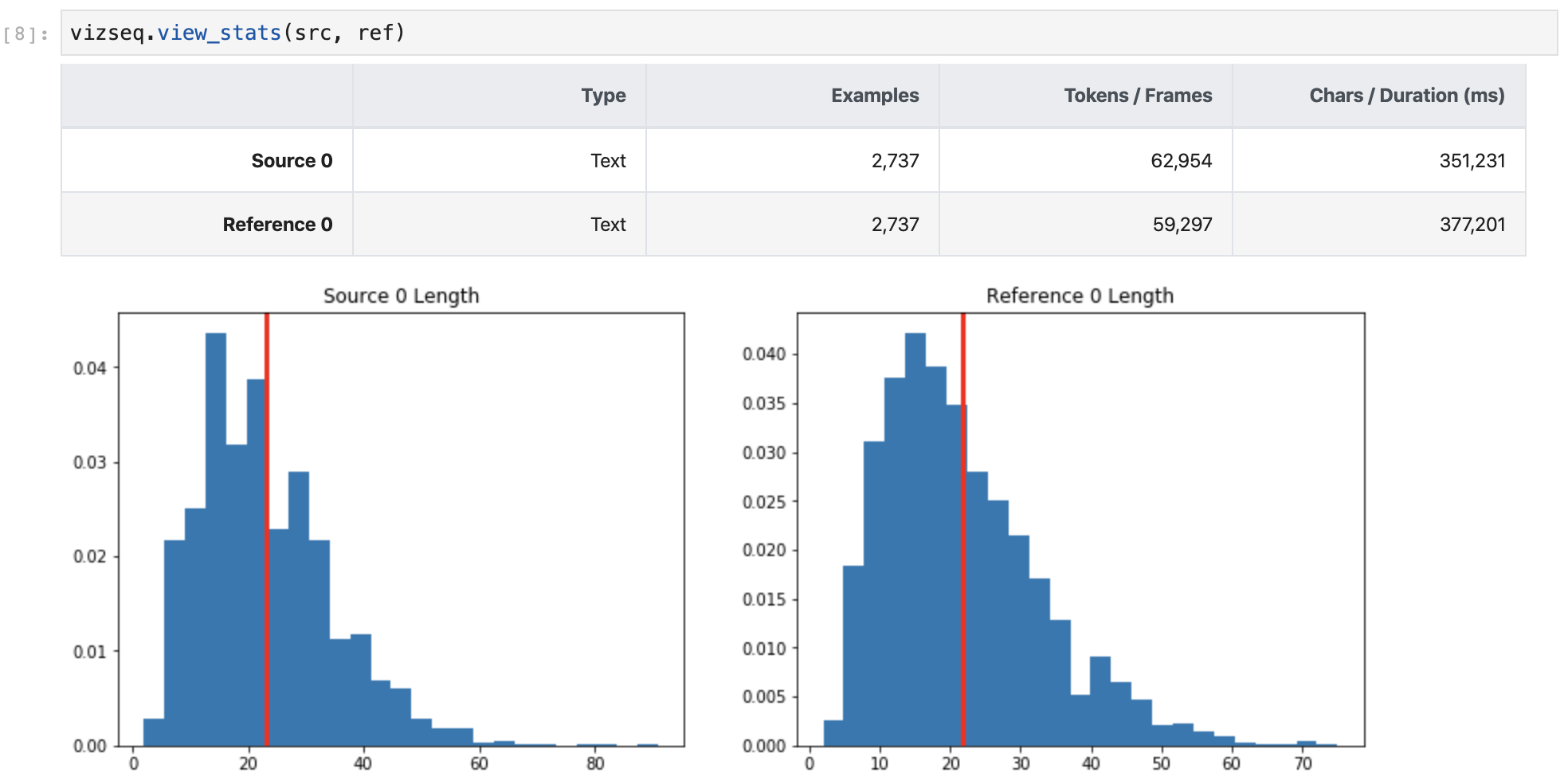
To view dataset statistics:
%matplotlib inlinevizseq.view_stats(src, ref)
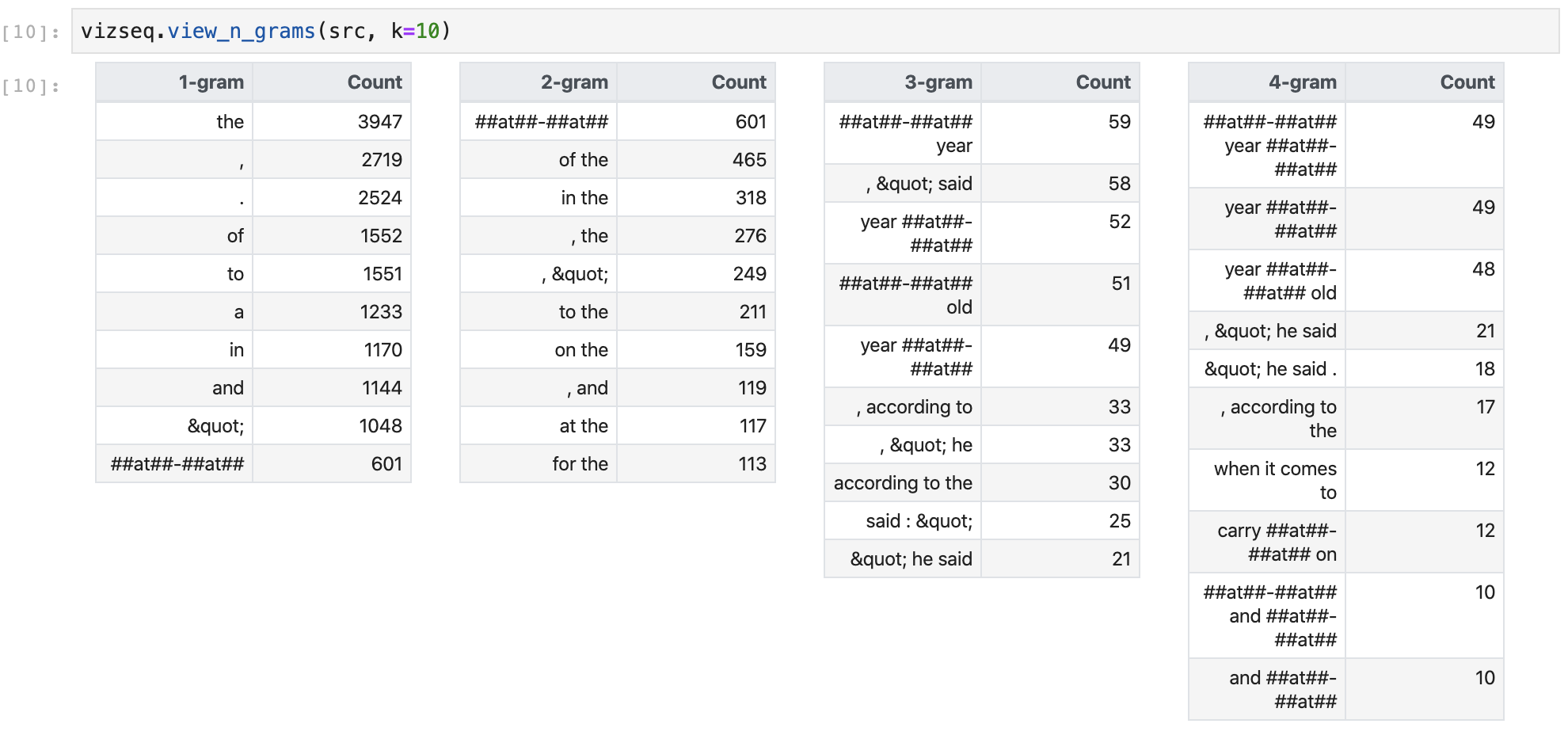
To view source-side n-grams:
vizseq.view_n_grams(src)
To view corpus-level scores (BLEU and METEOR):
vizseq.view_scores(ref, hypo, ['bleu', 'meteor'])

To check the IDs of available scorers in VizSeq:
vizseq.available_scorers()
Available scorers: bert_score, bleu, bp, chrf, cider, gleu, laser, meteor, nist, ribes, rouge_1, rouge_2, rouge_l, ter, wer, wer_del, wer_ins, wer_sub
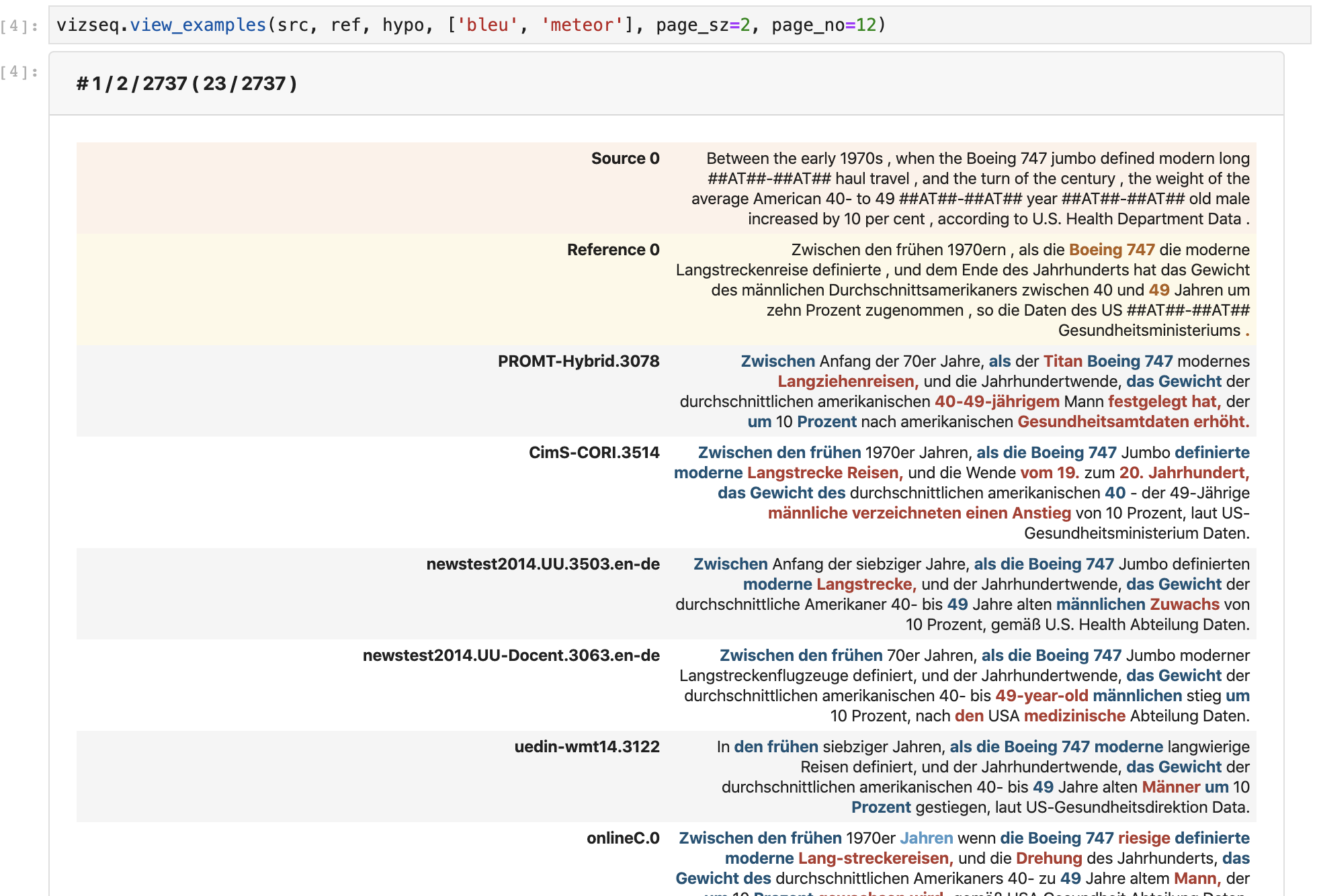
We can view examples in pages with sorting:
import vizseq.VizSeqSortingTypevizseq.view_examples(src, ref, hypo, ['bleu'], page_sz=2, page_no=12, sorting=VizSeqSortingType.src_len)
Google Translate Integration
VizSeq integrates Google Translate using Google Cloud API, to use which you need a Google Cloud credential and let VizSeq know the credential JSON file path:
vizseq.set_google_credential_path('path to google credential json file')
Then in example viewing API, simply switch the need_g_translate argument on:
vizseq.view_examples(src, ref, hypo, ['bleu'], need_g_translate=True)