Efficient Benchmarking¶
What you will learn
How to benchmark language model training and inference
How to perform systematic hyperparameter sweeps
How to profile model performance using torch profiler
How to scale training to multiple nodes efficiently
Prerequisites
Get familiar with fairseq2 basics ( Overview)
Ensure you have fairseq2 installed ( Installation)
Understand how to use built-in presets ( Working with Presets)
Familiarize yourself with recipes (Recipe)
Understand how to use CLI (CLI)

Overview¶
This tutorial will guide you through conducting systematic benchmarks using fairseq2. We’ll focus on practical examples using language models, covering:
Training speed benchmarks
Multi-node scaling efficiency
Hyperparameter sweeps
Performance profiling
Note
The examples will use LLaMA models, but the concepts apply to any model architecture.
Training Speed Benchmarks¶
Let’s start by benchmarking the training speed of different model configurations.
1. Environment Setup¶
First, set up different virtual environments to test various PyTorch configurations.
Example Environment Setup
# Create environments with different PyTorch versions
conda create -n fairseq2_pt22 python=3.10
conda create -n fairseq2_pt24 python=3.10
# Install PyTorch 2.2 environment
conda activate fairseq2_pt22
pip install torch==2.2.0 --index-url https://download.pytorch.org/whl/cu121
pip install fairseq2
# Install PyTorch 2.4 environment
conda activate fairseq2_pt24
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
pip install fairseq2
Note
Follow the instructions in Installation to install fairseq2 and PyTorch.
2. Multi-Node Training¶
fairseq2 CLI is designed to support distributed training across multiple nodes, and it facilitates the sweeping of hyperparameters across different environments.
Example SLURM Script
#!/bin/bash
#SBATCH --job-name=fairseq2_benchmark
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=8
#SBATCH --gpus-per-node=8
# List of environments to test
envs=(
"fairseq2_pt22"
"fairseq2_pt24"
)
# Run benchmarks
for env_name in "${envs[@]}"; do
conda activate $env_name
for i in {0..1}; do # Two runs per environment
echo "Running $env_name run $i"
srun fairseq2 lm instruction_finetune \
--preset llama3_1_70b_instruct \
--config-file configs/benchmark.yaml \
-- benchmark_outputs/${env_name}/run_${i} # output directory
done
conda deactivate
done
Example benchmark.yaml
# Training config
max_num_steps: 1000
batch_size: 4
max_seq_len: 2048
# Distributed training
data_parallelism: "fsdp"
tensor_parallel_size: 8
# Optimization
optimizer:
lr: 2e-5
weight_decay: 0.1
mixed_precision: "static"
dtype: "bfloat16"
Hyperparameter Sweeps¶
fairseq2 provides powerful sweep functionality with its fairseq2.recipes.utils.sweep_tagger.SweepTagger.
It helps ensure:
Consistent directory structure across nodes
Reproducible experiments
Easy comparison of different configurations
For example, when running multi-node training:
#!/bin/bash
#SBATCH --job-name=mt_sweep
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=8
#SBATCH --gpus-per-node=8
# Language pairs to sweep
lang_pairs=(
"eng-fra"
"eng-deu"
"eng-spa"
)
# Run MT sweeps
for pair in "${lang_pairs[@]}"; do
src_lang=${pair%-*}
tgt_lang=${pair#*-}
# fairseq2 CLI will automatically use SweepTagger to create
# a unique directory based on the config
srun fairseq2 mt train \
--preset nllb_600m \
--config-file configs/mt.yaml \
--config source_lang=$src_lang target_lang=$tgt_lang \
-- sweep_outputs/ # Base output directory
The fairseq2 CLI will:
Parse the config file and command line overrides
Use
fairseq2.recipes.utils.sweep_tagger.SweepTaggerto generate a unique tag based on sweep keysCreate a subdirectory using this tag under the base output directory
Ensure all nodes write to the same directory structure
If
fmtis provided, it will be used to generate the tag in a customizable format
Note
Use --no-sweep-dir when you want to disable automatic sweep directory creation. This is useful when:
Running quick tests/debugging
Using custom directory structures
Different recipes support different sweep keys. The following examples will show how to configure sweep tags for different recipes.
1. Language Model Sweeps¶
For language models, we have two main finetuning approaches.
Instruction Finetuning (SFT)
from fairseq2.recipes.lm.instruction_finetune import (
InstructionFinetuneConfig,
instruction_finetune_presets
)
from fairseq2.recipes.utils.sweep_tagger import SweepTagger
# Configure LM sweep
sweep_keys = {
"batch_size",
"max_seq_len",
"dtype",
"tensor_parallel_size"
}
sweep_tagger = SweepTagger(world_size=8, allowed_keys=sweep_keys)
# Example instruction finetuning config
config = {
"max_num_steps": 1000,
"batch_size": 4,
"max_seq_len": 2048,
"dtype": "bfloat16"
}
# Generate unique tag for this config
tag = sweep_tagger.generate(
"llama3_1_70b_instruct",
config,
fmt="ps_{preset}.ws_{world_size}.{batch_size}_{max_seq_len}_{dtype}",
)
output_dir = Path(f"sweep_outputs/{tag}")
Preference Finetuning (DPO)
from fairseq2.recipes.lm.preference_finetune.dpo import (
DpoConfig,
create_dpo_unit
)
from fairseq2.recipes.utils.sweep_tagger import SweepTagger
# Configure DPO sweep
sweep_keys = {
"batch_size",
"max_seq_len",
"beta", # DPO-specific
"nll_scale", # DPO-specific
"reference_tensor_parallel_size", # DPO-specific
"length_normalization" # DPO-specific
}
sweep_tagger = SweepTagger(world_size=8, sweep_keys=sweep_keys)
# Example DPO config
config = {
"max_num_steps": 1000,
"batch_size": 4,
"max_seq_len": 2048,
"beta": 0.1,
"nll_scale": 0.0,
"reference_model": "llama3_1_8b_instruct",
"reference_tensor_parallel_size": 1,
"length_normalization": False
}
# Generate unique tag for this config
tag = sweep_tagger.generate("llama3_1_8b_dpo", config)
output_dir = Path(f"sweep_outputs/{tag}")
Example SLURM script for running DPO sweeps:
#!/bin/bash
#SBATCH --job-name=dpo_sweep
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=8
#SBATCH --gpus-per-node=8
# List of beta values to sweep
betas=(0.1 0.2 0.5)
# Run DPO sweeps
for beta in "${betas[@]}"; do
srun fairseq2 lm preference_finetune \
--preset llama3_1_8b_dpo \
--config-file configs/dpo.yaml \
--config "beta=$beta"
-- sweep_outputs/
done
2. Machine Translation Sweeps¶
MT recipes include additional sweep keys specific to translation tasks.
Example MT sweep
from fairseq2.recipes.mt.train import load_mt_trainer, mt_train_presets
from fairseq2.recipes.utils.sweep_tagger import SweepTagger
# Configure MT sweep
sweep_keys = {
"lr",
"weight_decay",
"source_lang", # MT-specific
"target_lang", # MT-specific
"max_seq_len",
"batch_size"
}
sweep_tagger = SweepTagger(world_size=8, sweep_keys=sweep_keys)
# Example MT config
config = {
"source_lang": "eng",
"target_lang": "fra",
"optimizer_config": {
"lr": 2e-5,
"weight_decay": 0.1
}
}
# Generate unique tag for this config
tag = sweep_tagger.generate("nllb_600m", config)
output_dir = Path(f"sweep_outputs/{tag}")
3. wav2vec2 Sweeps¶
Speech models also have their own set of sweep parameters:
Example wav2vec2 sweep
from fairseq2.models.wav2vec2.asr import wav2vec2_asr_archs from fairseq2.recipes.utils.sweep_tagger import SweepTagger # wav2vec2-specific sweep keys sweep_keys = { "freeze_encoder_for_n_steps", "max_audio_len", "min_audio_len", "normalize_audio", } sweep_tagger = SweepTagger(world_size=8, allowed_keys=sweep_keys) # Example wav2vec2 config config = { "freeze_encoder_for_n_steps": 1_000, "max_audio_len": 100_000, "min_audio_len": 1_000, "normalize_audio": True } # Generate unique tag for this config tag = sweep_tagger.generate( "wav2vec2_base", config, fmt="ps_{preset}.ws_{world_size}.mal_{max_audio_len}.minal_{min_audio_len}.norm_{normalize_audio}", ) output_dir = Path(f"sweep_outputs/{tag}")
Performance Profiling¶
fairseq2 uses PyTorch’s profiler to help analyze performance bottlenecks. The profiler results will be saved to TensorBoard format in the output directory. It allows you to visualize the performance of your model in detail. It is also a useful tool for gathering performance metrics for hyperparameter sweeps.
Analysis of Profiler Results
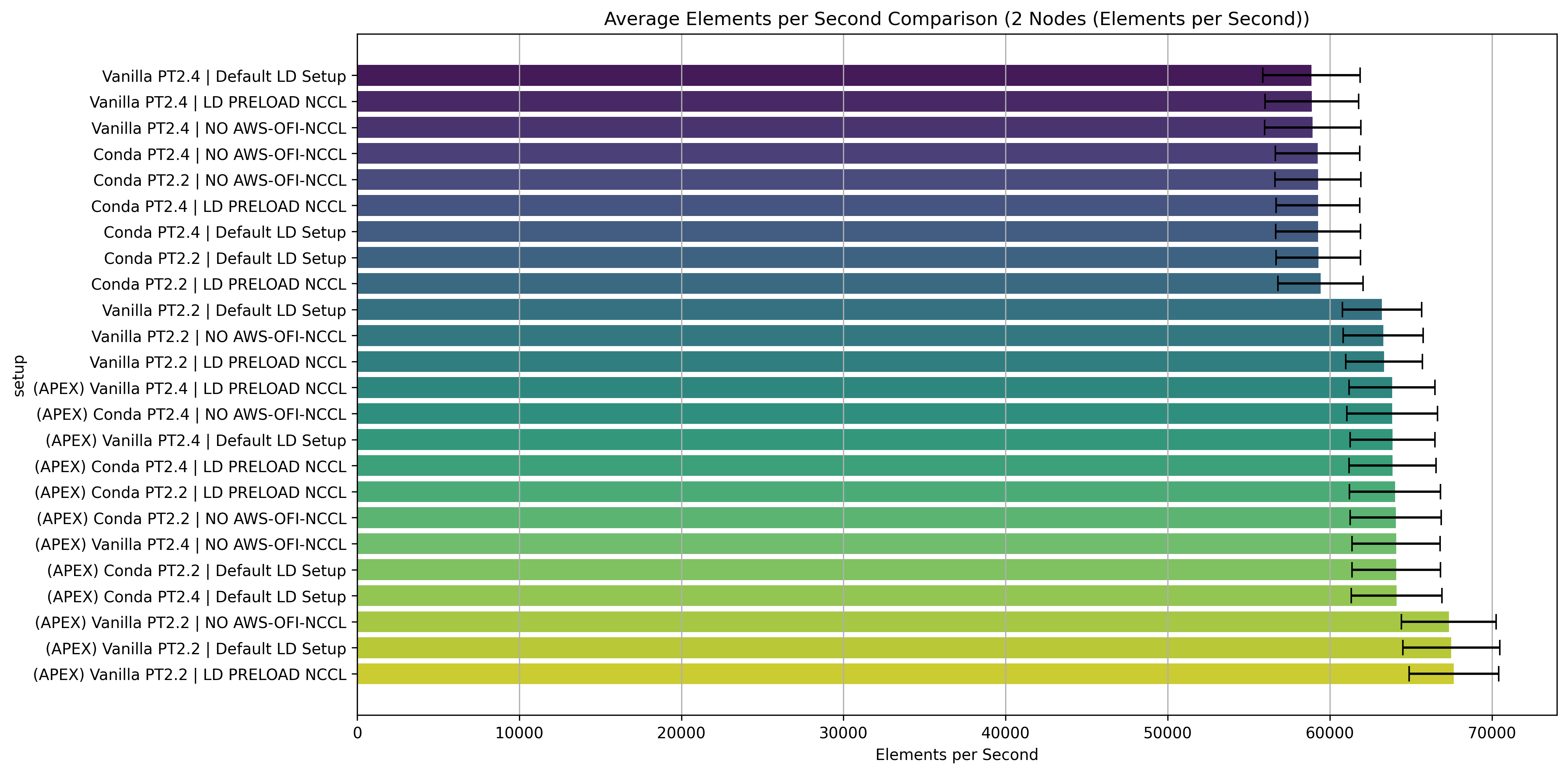
To visualize the results, start Tensorboard at the output directory:
# Start Tensorboard
tensorboard --logdir ./profile_outputs/tb/
Access the results in your browser at http://localhost:6006.
You can also plot the results in a customized way for your own analysis:
from tensorboard.backend.event_processing import event_accumulator
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def parse_tensorboard(path, scalars):
ea = event_accumulator.EventAccumulator(
path,
size_guidance={event_accumulator.SCALARS: 0},
)
ea.Reload()
return {k: pd.DataFrame(ea.Scalars(k)) for k in scalars}
def analyze_performance(log_dir):
# Parse metrics
metrics = parse_tensorboard(log_dir, ["Wall Time"]) # or "Elements per Second", "Elapsed Time"
# Calculate statistics
wall_time = metrics["Wall Time"]
steps_per_second = len(wall_time) / wall_time["value"].sum()
# Visualize
plt.figure(figsize=(10, 6))
sns.lineplot(data=wall_time, x="step", y="value")
plt.title("Training Wall Time per Step")
plt.show()
return steps_per_second
Best Practices¶
Systematic Benchmarking
Always benchmark with fixed seeds for reproducibility
Test multiple batch sizes and sequence lengths
Measure both training and validation performance
Record memory usage and throughput metrics
Distributed Training
Start with single-node tests before scaling to multiple nodes
Monitor communication overhead between nodes
Use FSDP for large models that don’t fit in GPU memory
Experiment with different tensor parallel sizes
Performance Optimization
Enable mixed precision training when possible
Tune gradient accumulation steps
Profile to identify bottlenecks
Monitor GPU utilization and memory usage