End-to-End Fine-Tuning¶
What you will learn
How to customize your assets (e.g. models, datasets, tokenizers)
How to run instruction fine-tuning recipe
How to use fairseq2 to generate (inference)
How to convert fairseq2 ckpt to huggingface ckpt for accelerated vllm inference
How to run fairseq2 with multiple nodes
Prerequisites
Get familiar with fairseq2 basics ( Overview)
Ensure you have fairseq2 installed ( Installation)
Overview¶
Prepare
Download the LLaMA3.2 1B model from HuggingFace
Download the gsm8k data prepared for this tutorial
Fine-Tune
One simple command to run the instruction fine-tuning recipe
Accelerate the training with multiple nodes
Generate
One simple command to generate from the finetuned model
Convert fairseq2 model ckpt to hf ckpt for accelerated vllm inference
Go Beyond
Use fairseq2 to accelerate your research
Prepare¶
Model¶
Follow the HuggingFace Models Tutorial to download the LLaMA3.2 1B model, which can be run on volta32gb GPUs.
Once you have the model in your local path, (e.g.` /models/Llama-3.2-1B/original/consolidated.00.pth),
you need to put the model in a YAML card so that fairseq2 will know from where to pull the model
(read more about Assets). To do that:
Create a YAML file (e.g.
my_llama3_2_1b.yaml) with the following content:
name: llama3_2_1b@user
checkpoint: "/models/Llama-3.2-1B/original/consolidated.00.pth"
---
name: llama3@user
tokenizer: "/models/Llama-3.2-1B/original/tokenizer.model"
Tip
The @user specifies this is your special environment. This can also be extended to help resolve different domain name for your clusters
Save the file in one of the following locations:
Option 1: Place it in the default fairseq2 asset directory
mkdir -p ~/.config/fairseq2/assetsmv my_llama3_2_1b.yaml ~/.config/fairseq2/assets/
Option 2: Specify a custom directory and point
FAIRSEQ2_USER_ASSET_DIRto itexport FAIRSEQ2_USER_ASSET_DIR=/path/to/custom/asset/directorymv my_llama3_2_1b.yaml /path/to/custom/asset/directory/
You can check out the predefined fairseq2 LLaMA model cards here.
Dataset¶
Follow the HuggingFace Datasets Tutorial to download the gsm8k data, (formatted with fairseq2 flavor) to your local path (e.g. /datasets/facebook/fairseq2-lm-gsm8k/).
We will use the sft/train.jsonl to fine-tune the model and use the test/test.jsonl for evaluation.
Fine-Tuning¶
One-Liner¶
Running the Supervised Fine-Tuning (SFT) recipe is as simple as:
fairseq2 lm instruction_finetune $OUTPUT_DIR --config \
dataset.path=/datasets/facebook/fairseq2-lm-gsm8k/sft \
model.name=llama3_2_1b \
dataset.max_seq_len=4096 \
dataset.max_num_tokens=4096 \
trainer.dtype=float16 \
regime.num_steps=1000 \
regime.num_data_epochs=20 \
regime.checkpoint_every_n_steps=1000
Similarly, we have the Direct Preference Optimization (DPO) recipe:
fairseq2 lm preference_finetune $OUTPUT_DIR --config ...
Read more about this recipe in Preference Optimization.
You can also put the configuration in a YAML file
# /configs/example.yaml
dataset:
_set_:
path: /datasets/facebook/fairseq2-lm-gsm8k/sft
max_seq_len: 4096
max_num_tokens: 4096
model:
_set_:
name: llama3_2_1b
trainer:
_set_:
dtype: float16 # volta32gb gpus do not support bfloat16
regime:
_set_:
num_steps: 1000
num_data_epochs: 20
checkpoint_every_n_steps: 1000
keep_last_n_checkpoints: 1
publish_metrics_every_n_steps: 5
Then run:
CONFIG_FILE=/configs/example.yaml
fairseq2 lm instruction_finetune $OUTPUT_DIR --config-file $CONFIG_FILE
For more details about the recipe configuration, please refer to Recipes.
Dumping Configuration¶
For a quick overview of all the sections and fields, you can use the --dump-config command:
fairseq2 lm instruction_finetune --dump-config
Iterative Training¶
Sometimes you may want to continue fine-tuning from a previously trained checkpoint, either to:
Resume interrupted training
Fine-tune on additional data
Perform iterative fine-tuning with different hyperparameters
fairseq2 provides a clean way to handle this through the checkpoint system (learn more about Checkpoint Management):
fairseq2 lm instruction_finetune $OUTPUT_DIR --config \
common.assets.checkpoint_dir=/path/to/checkpoint \
model.name=last_checkpoint \ # this will pick up the last checkpoint
dataset.path=/path/to/data
To pick up a specific checkpoint
CKPT_DIR="/checkpoint/user/experiments/run_0/checkpoints"
CKPT="checkpoint_step_1000" # e.g. checkpoint of step 1000
fairseq2 lm instruction_finetune $OUTPUT_DIR --config \
common.assets.checkpoint_dir=$CKPT_DIR \
model.name=$CKPT \
dataset.path=/path/to/new/data \
dataset.max_num_tokens=4096 \
trainer.dtype=float16
Note
If you want to pick a specific checkpoint instead of the last checkpoint, the model parameter must be set to checkpoint_step_X where X matches the step number of the checkpoint you want to load.
A more detailed example
For iterative fine-tuning across different datasets or with different hyperparameters:
# config.yaml
# First stage - train on dataset A
dataset:
_set_:
path: /path/to/dataset_A
model:
_set_:
name: llama3_2_1b
regime:
_set_:
num_steps: 1000
optimizer:
_set_:
name: adamw
config:
_set_:
lr: 1e-5
# ... other config
Then run the following commands in bash:
# First stage
fairseq2 lm instruction_finetune run1_output --config-file config.yaml
# Second stage - continue from first stage checkpoint
fairseq2 lm instruction_finetune run2_output --config \
common.assets.checkpoint_dir=run1_output/checkpoints \
model.name=checkpoint_step_1000 \
dataset.path=/path/to/dataset_B \
optimizer.config.lr=5e-6 # Lower learning rate for second stage
regime.num_steps=500
Tip
When doing iterative fine-tuning:
Generally use a lower learning rate in later stages
Consider reducing the number of steps for later stages
You may want to adjust the validation frequency
Make sure to track metrics to compare performance across stages
Multi-Node¶
To help accelerate the training, fairseq2 is able to automatically detect multi-node setup.
Option 1: Slurm
srun --pty --nodes=2 --ntasks-per-node=8 --gpus-per-node=8 \ fairseq2 lm instruction_finetune $OUTPUT_DIR \ ...
Option 2: Torchrun
torchrun --standalone --nproc-per-node 8 --no-python \ fairseq2 lm instruction_finetune $OUTPUT_DIR \ ...
Generate¶
Once you have finished the training, you can find in the $OUTPUT_DIR the model checkpoints in $OUTPUT_DIR/checkpoints. With that, we can now generate over the test dataset!
Native Support¶
fairseq2 natively supports inference:
CKPT_DIR="/checkpoint/$USER/my_experiment/checkpoints"
CKPT="last_checkpoint"
SAVE_DIR="/checkpoint/$USER/my_experiment/generations"
DATASET="/datasets/facebook/fairseq2-lm-gsm8k/test/test.jsonl"
fairseq2 lm generate $SAVE_DIR --no-sweep-dir --config \
common.assets.checkpoint_dir=$CKPT_DIR \
model.name=$CKPT \
seq_generator.config.temperature=0.1 \
dataset.path=$DATASET
vLLM Support¶
vLLM natively supports fairseq2 LLaMA checkpoint files. To accelerate the inference process, we can deploy fairseq2 LLaMA checkpoints with VLLM. This is done by pointing vLLM to both the fairseq2 checkpoint directory and the Hugging Face tokenizer:
from vllm import LLM
llm = LLM(
model=<path_to_fs2_checkpoint>, # path of your model
tokenizer=<name_or_path_of_hf_tokenizer>, # path of your tokenizer files
)
output = llm.generate("Hello, my name is")
print(output)
Please refer to the VLLM documentation for more details.
Check the Accuracy¶
Once you generated the output, it is relatively trivial to compute the accuracy. Overall, you just need to:
Load the generated dataset
Load the original test dataset as ground truth
Compare and count the number of correct items
Some example utils functions
import re
ANS_RE = re.compile(r"#### (\-?[0-9\.\,]+)")
INVALID_ANS = "[invalid]"
def extract_answer(completion: str) -> str:
"""
Extract the answer from the completion.
:param completion: The completion.
:return: The answer.
"""
global ANS_RE, INVALID_ANS
match = ANS_RE.search(completion)
if match:
match_str = match.group(1).strip()
match_str = match_str.replace(",", "")
return match_str
else:
return INVALID_ANS
def is_correct(model_completion: str, gt_example: str) -> bool:
"""
Check if the model completion is correct.
:param model_completion: The model completion.
:param gt_example: The ground truth example.
:return: True if the model completion is correct, False otherwise.
"""
gt_answer = extract_answer(gt_example)
assert gt_answer != INVALID_ANS
return extract_answer(model_completion) == gt_answer
Go Beyond¶
That’s pretty much it to get you started. But you can do a lot more. fairseq2 is a powerful tool to help you accelerate and scale up your research. It allows:
Experiment with different hyper-parameter configurations;
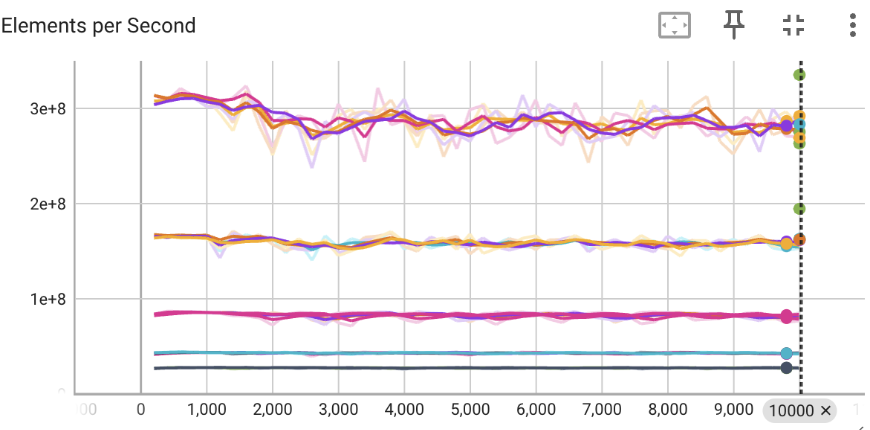
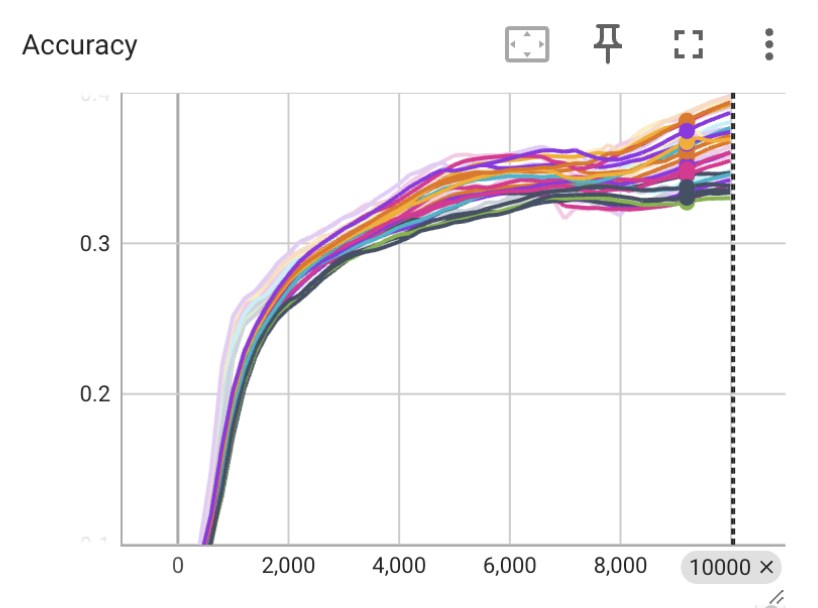
Compare performance across various datasets or model architectures;
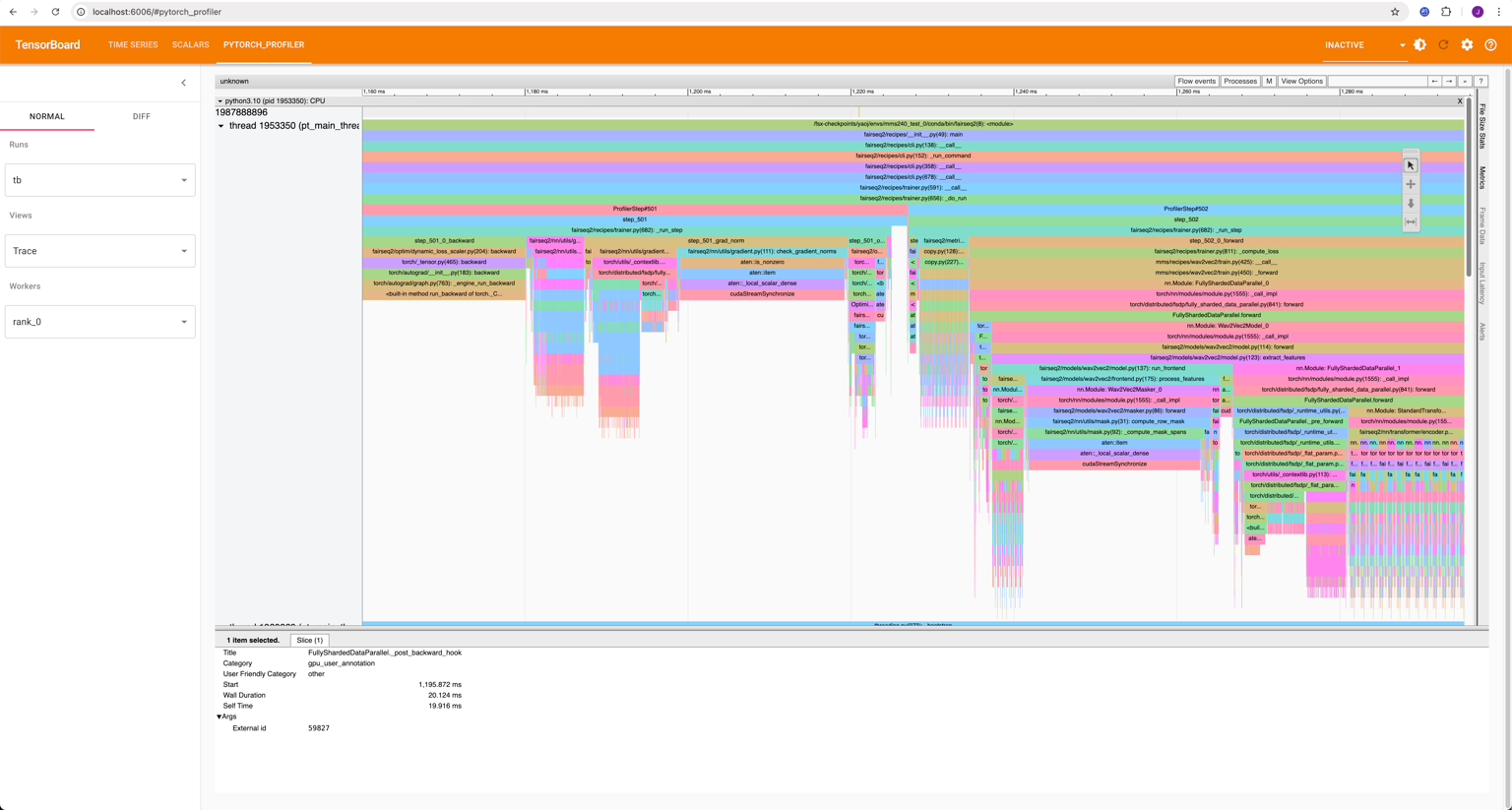
Profile resource usage and optimize training workflows;
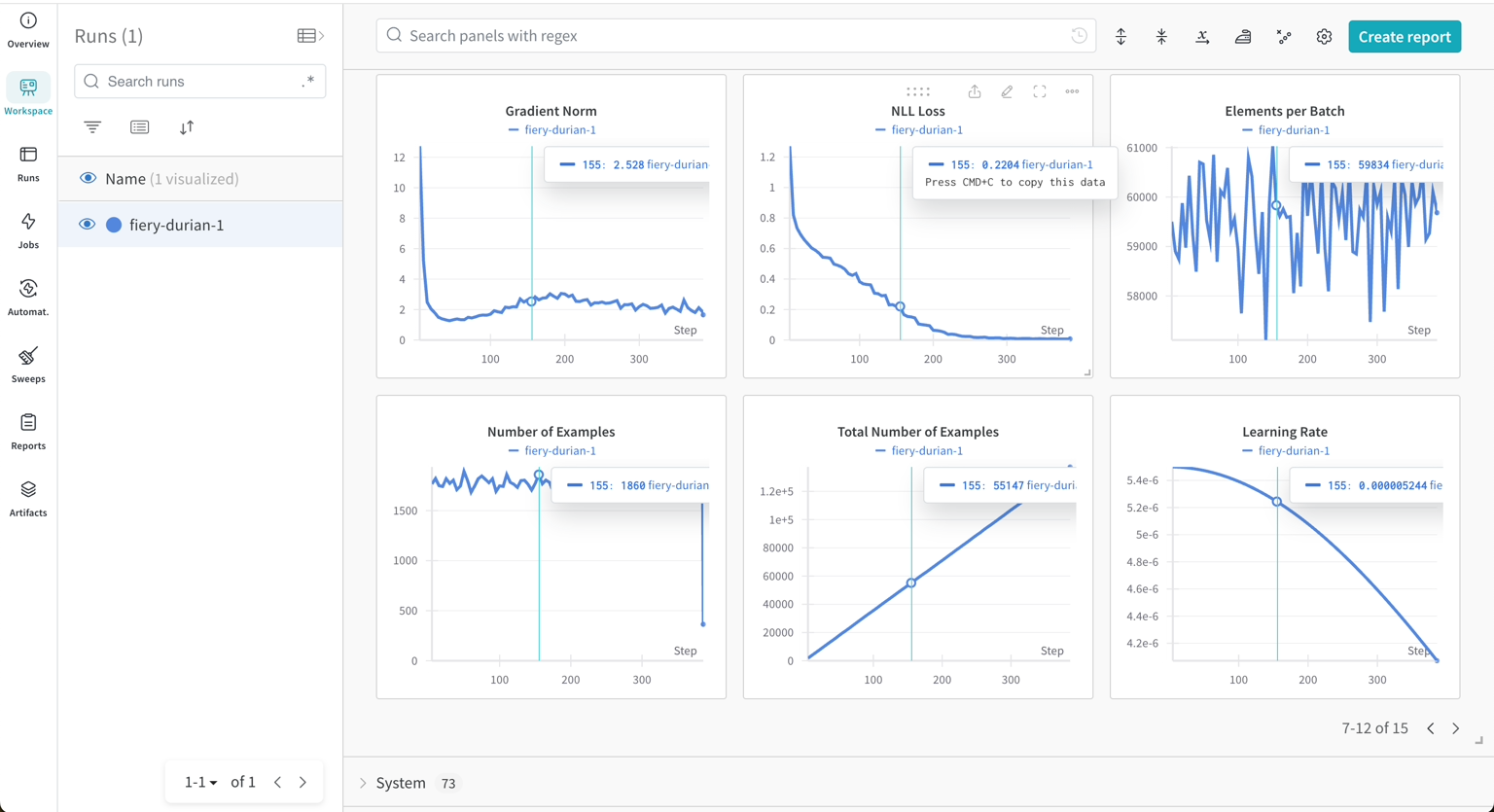
Connect to your WanDB and monitor your experiments in real-time;
Now, up for you to discover!!!