Performance analysis¶
This example shows how to collect runtime performance statistics using custom hooks and then export the data to a database.
Note
To learn how to interpret the performance statistics, please refer to Optimization Guide.
The Pipeline class can collect runtime statistics
and periodically publish them via hooks and queues.
This example shows how to use a buffer-based logging pattern with
SQLite as the storage backend to collect and query performance statistics.
The performance stats are exposed as spdl.pipeline.TaskPerfStats and
spdl.pipeline.QueuePerfStats classes. These are collected via hooks
and queues into a shared buffer, which is then asynchronously written
to a SQLite database by a dedicated writer thread.
Architecture¶
The following diagram illustrates the relationship between the pipeline, buffer, and writer thread:
Example Usage¶
This example demonstrates:
Using
TaskStatsHookWithLoggingto log task performance to a bufferUsing
StatsQueueWithLoggingto log queue performance to a bufferUsing
SQLiteStatsWriterto asynchronously flush the buffer to SQLite
Running this example on Kinetics K400 dataset produces the following output:
================================================================================
PIPELINE PERFORMANCE SUMMARY
================================================================================
📊 Task Statistics:
--------------------------------------------------------------------------------
Stage: 0:1:decode[10]
Total tasks processed: 240435
Total failures: 1458
Average task time: 0.4241s
Success rate: 99.4%
Number of log entries: 169
📈 Queue Statistics:
--------------------------------------------------------------------------------
Queue: 0:0:src_queue
Total items processed: 240445
Average QPS: 23.71
Average put time: 0.0417s
Average get time: 0.0000s
Average occupancy rate: 100.0%
Number of log entries: 169
Queue: 0:1:decode[10]_queue
Total items processed: 238977
Average QPS: 23.57
Average put time: 0.0000s
Average get time: 0.0424s
Average occupancy rate: 0.1%
Number of log entries: 169
Queue: 0:2:sink_queue
Total items processed: 238977
Average QPS: 23.57
Average put time: 0.0000s
Average get time: 0.0421s
Average occupancy rate: 0.1%
Number of log entries: 169
Visualization¶
The SQLite database can be queried using standard SQL tools or the built-in query API to analyze:
Task execution times and failure rates
Queue throughput (QPS) and occupancy rates
Pipeline bottlenecks and resource utilization
You can use the performance_analysis_plot.py script to query the data from
the database and generate plots for visualization and analysis.
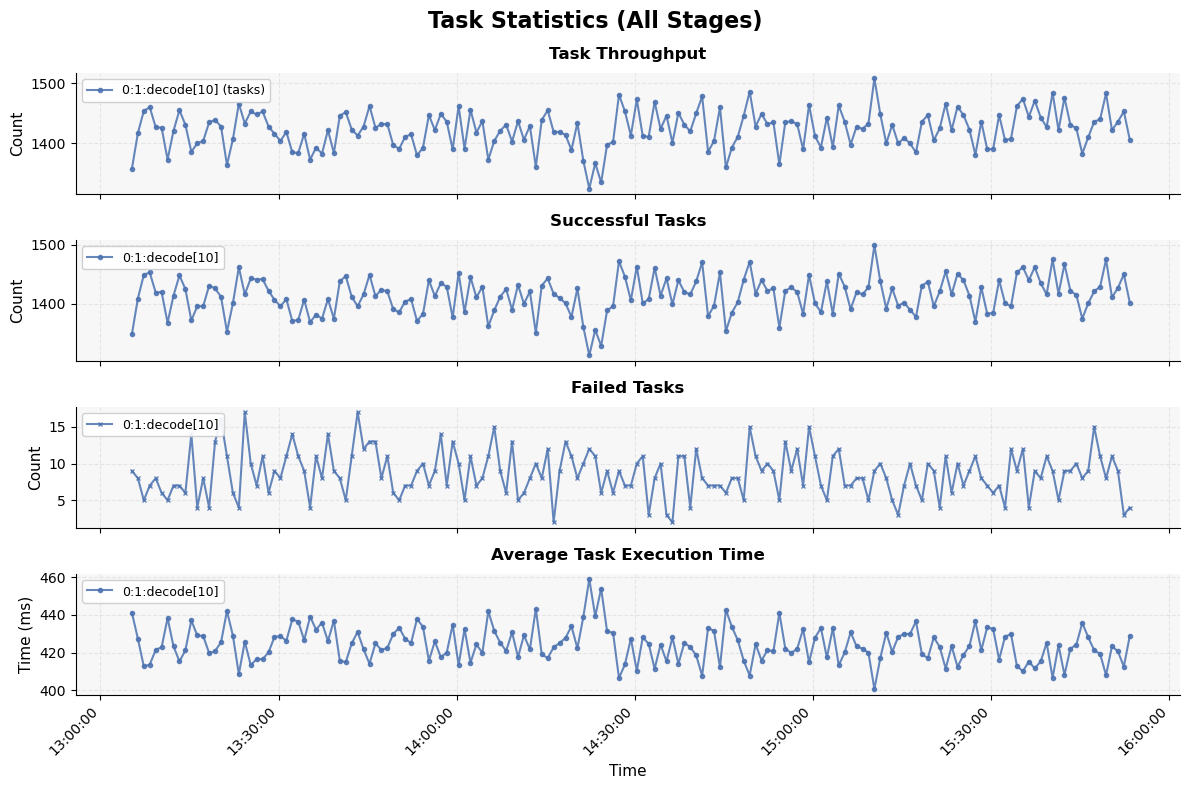
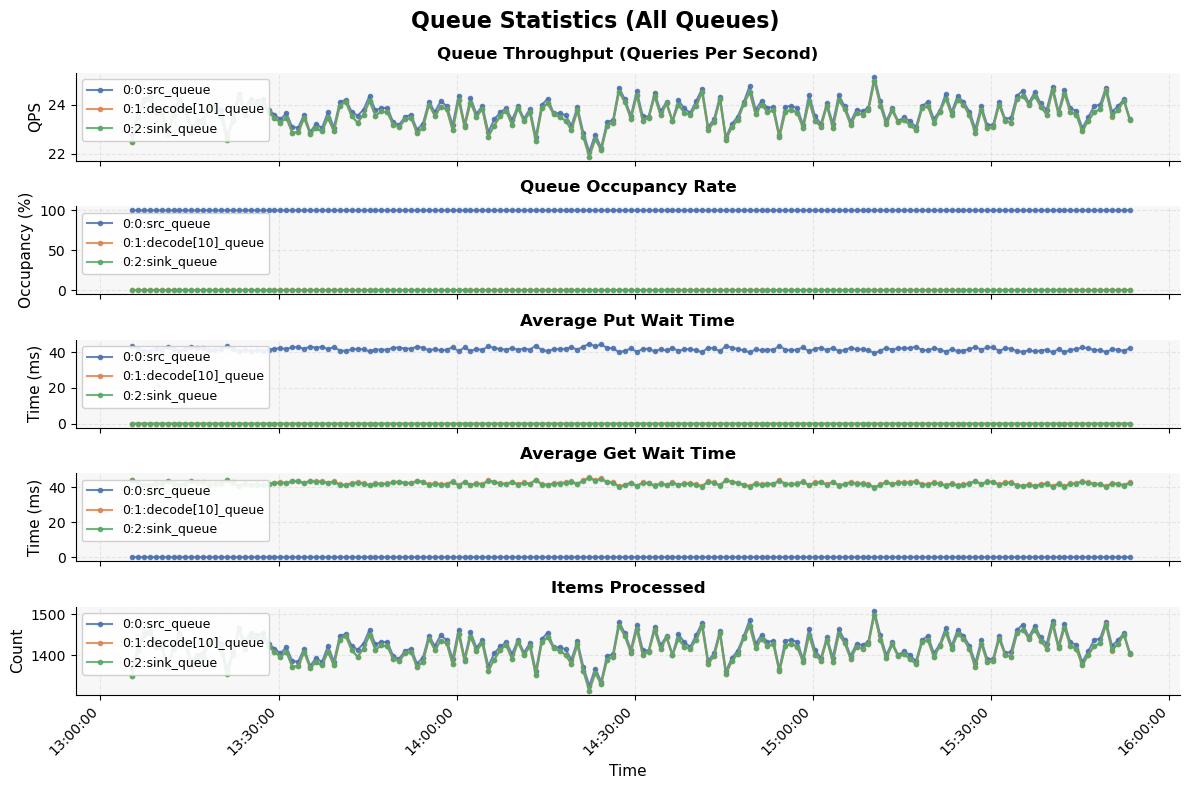
Source¶
Source
Click here to see the source.
1#!/usr/bin/env python3
2# Copyright (c) Meta Platforms, Inc. and affiliates.
3# All rights reserved.
4#
5# This source code is licensed under the BSD-style license found in the
6# LICENSE file in the root directory of this source tree.
7
8"""This example shows how to collect runtime performance statistics using
9custom hooks and then export the data to a database.
10
11.. note::
12
13 To learn how to interpret the performance statistics, please refer to
14 `Optimization Guide <../performance_analysis/index.html>`_.
15
16The :py:class:`~spdl.pipeline.Pipeline` class can collect runtime statistics
17and periodically publish them via hooks and queues.
18This example shows how to use a buffer-based logging pattern with
19SQLite as the storage backend to collect and query performance statistics.
20
21The performance stats are exposed as :py:class:`spdl.pipeline.TaskPerfStats` and
22:py:class:`spdl.pipeline.QueuePerfStats` classes. These are collected via hooks
23and queues into a shared buffer, which is then asynchronously written
24to a SQLite database by a dedicated writer thread.
25
26Architecture
27------------
28
29The following diagram illustrates the relationship between the pipeline, buffer,
30and writer thread:
31
32.. mermaid::
33
34 graph LR
35 subgraph Pipeline
36 A[Task Hooks]
37 C[Queues]
38 end
39 A -->|Task Stats| B[Shared Buffer]
40 C -->|Queue Stats| B
41 D[GC Events] -->|Event Logs| B
42 B -->|Async Write| E[Writer Thread]
43 E -->|Persist| F[(SQLite Database)]
44 F -->|Query| G[performance_analysis_plot.py]
45
46Example Usage
47-------------
48
49This example demonstrates:
50
51#. Using :py:class:`TaskStatsHookWithLogging` to log task performance to a buffer
52#. Using :py:class:`StatsQueueWithLogging` to log queue performance to a buffer
53#. Using :py:class:`SQLiteStatsWriter` to asynchronously flush the buffer to SQLite
54
55Running this example on Kinetics K400 dataset produces the following output:
56
57.. code-block:: text
58
59 ================================================================================
60 PIPELINE PERFORMANCE SUMMARY
61 ================================================================================
62 📊 Task Statistics:
63 --------------------------------------------------------------------------------
64
65 Stage: 0:1:decode[10]
66 Total tasks processed: 240435
67 Total failures: 1458
68 Average task time: 0.4241s
69 Success rate: 99.4%
70 Number of log entries: 169
71
72 📈 Queue Statistics:
73 --------------------------------------------------------------------------------
74
75 Queue: 0:0:src_queue
76 Total items processed: 240445
77 Average QPS: 23.71
78 Average put time: 0.0417s
79 Average get time: 0.0000s
80 Average occupancy rate: 100.0%
81 Number of log entries: 169
82
83 Queue: 0:1:decode[10]_queue
84 Total items processed: 238977
85 Average QPS: 23.57
86 Average put time: 0.0000s
87 Average get time: 0.0424s
88 Average occupancy rate: 0.1%
89 Number of log entries: 169
90
91 Queue: 0:2:sink_queue
92 Total items processed: 238977
93 Average QPS: 23.57
94 Average put time: 0.0000s
95 Average get time: 0.0421s
96 Average occupancy rate: 0.1%
97 Number of log entries: 169
98
99Visualization
100-------------
101
102The SQLite database can be queried using standard SQL tools or the
103built-in query API to analyze:
104
105- Task execution times and failure rates
106- Queue throughput (QPS) and occupancy rates
107- Pipeline bottlenecks and resource utilization
108
109You can use the ``performance_analysis_plot.py`` script to query the data from
110the database and generate plots for visualization and analysis.
111
112.. image:: ../_static/data/example-performance-analysis-task-stats.png
113
114.. image:: ../_static/data/example-performance-analysis-queue-stats.png
115
116"""
117
118import argparse
119import gc
120import logging
121import time
122from collections.abc import Iterable
123from functools import partial
124from pathlib import Path
125from queue import Queue
126
127import spdl.io
128import torch
129from spdl.pipeline import (
130 Pipeline,
131 PipelineBuilder,
132 QueuePerfStats,
133 StatsQueue,
134 TaskHook,
135 TaskPerfStats,
136 TaskStatsHook,
137)
138
139try:
140 from examples.sqlite_stats_logger import ( # pyre-ignore[21]
141 EventLogEntry,
142 log_stats_summary,
143 QueueStatsLogEntry,
144 SQLiteStatsWriter,
145 TaskStatsLogEntry,
146 )
147except ImportError:
148 from spdl.examples.sqlite_stats_logger import (
149 EventLogEntry,
150 log_stats_summary,
151 QueueStatsLogEntry,
152 SQLiteStatsWriter,
153 TaskStatsLogEntry,
154 )
155
156
157__all__ = [
158 "parse_args",
159 "main",
160 "build_pipeline",
161 "decode",
162 "TaskStatsHookWithLogging",
163 "StatsQueueWithLogging",
164 "SQLiteStatsWriter",
165]
166
167# pyre-strict
168
169_LG: logging.Logger = logging.getLogger(__name__)
170
171
172class TaskStatsHookWithLogging(TaskStatsHook):
173 """Task hook that logs statistics to a shared buffer.
174
175 This hook collects task performance statistics and writes them to a
176 plain Python queue.
177
178 Args:
179 name: Name of the stage/task.
180 buffer: Shared queue to write stats entries. This queue is typically
181 consumed by a separate writer (e.g., ``SQLiteStatsWriter``).
182 interval: The interval (in seconds) to report the performance stats
183 periodically.
184 """
185
186 def __init__(
187 self,
188 name: str,
189 buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry],
190 interval: float = 59,
191 ) -> None:
192 super().__init__(name=name, interval=interval)
193 self._buffer = buffer
194
195 async def interval_stats_callback(self, stats: TaskPerfStats) -> None:
196 """Log interval statistics to the buffer."""
197 await super().interval_stats_callback(stats)
198
199 entry = TaskStatsLogEntry(
200 timestamp=time.time(),
201 name=self.name,
202 stats=stats,
203 )
204 self._buffer.put(entry)
205
206
207class StatsQueueWithLogging(StatsQueue):
208 """Queue that logs statistics to a shared buffer.
209
210 This queue collects queue performance statistics and writes them to a
211 plain Python queue.
212
213 Args:
214 name: Name of the queue. Assigned by PipelineBuilder.
215 buffer: Shared queue to write stats entries. This queue is typically
216 consumed by a separate writer (e.g., ``SQLiteStatsWriter``).
217 buffer_size: The buffer size. Assigned by PipelineBuilder.
218 interval: The interval (in seconds) to report the performance stats
219 periodically.
220 """
221
222 def __init__(
223 self,
224 name: str,
225 buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry],
226 buffer_size: int = 1,
227 interval: float = 59,
228 ) -> None:
229 super().__init__(name=name, buffer_size=buffer_size, interval=interval)
230 self._buffer = buffer
231
232 async def interval_stats_callback(self, stats: QueuePerfStats) -> None:
233 """Log interval statistics to the buffer."""
234 await super().interval_stats_callback(stats)
235
236 entry = QueueStatsLogEntry(
237 timestamp=time.time(),
238 name=self.name,
239 stats=stats,
240 )
241 self._buffer.put(entry)
242
243
244def parse_args() -> argparse.Namespace:
245 """Parse command line arguments."""
246 parser = argparse.ArgumentParser(
247 description=__doc__,
248 )
249 parser.add_argument(
250 "--dataset-dir",
251 type=Path,
252 required=True,
253 help="Directory containing video files (*.mp4)",
254 )
255 parser.add_argument(
256 "--db-path",
257 type=Path,
258 default=Path("pipeline_stats.db"),
259 help="Path to SQLite database for stats (default: pipeline_stats.db)",
260 )
261 parser.add_argument(
262 "--log-interval",
263 type=float,
264 default=60,
265 help="Interval in seconds for logging stats to database (default: 60)",
266 )
267 parser.add_argument(
268 "--concurrency",
269 type=int,
270 default=10,
271 help="Number of concurrent decoding tasks (default: 10)",
272 )
273 return parser.parse_args()
274
275
276def decode(path: Path, width: int = 128, height: int = 128) -> torch.Tensor:
277 """Decode the video from the given path with rescaling.
278
279 Args:
280 path: The path to the video file.
281 width,height: The resolution of video after rescaling.
282
283 Returns:
284 Uint8 tensor in shape of ``[N, C, H, W]``: Video frames in Tensor.
285 """
286 packets = spdl.io.demux_video(path)
287 frames = spdl.io.decode_packets(
288 packets,
289 filter_desc=spdl.io.get_filter_desc(
290 packets,
291 scale_width=width,
292 scale_height=height,
293 pix_fmt="rgb24",
294 ),
295 )
296 buffer = spdl.io.convert_frames(frames)
297 return spdl.io.to_torch(buffer).permute(0, 2, 3, 1)
298
299
300def build_pipeline(
301 source: Iterable[Path],
302 log_interval: float,
303 concurrency: int,
304 buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry],
305) -> Pipeline:
306 """Build the pipeline with stats logging to a buffer.
307
308 Args:
309 source: A data source containing video file paths.
310 log_interval: The interval (in seconds) the performance data is saved.
311 concurrency: The concurrency for video decoding.
312 buffer: Shared queue for collecting stats entries. This queue should
313 be consumed by a ``SQLiteStatsWriter`` instance.
314
315 Returns:
316 A configured Pipeline instance ready for execution.
317 """
318
319 def hook_factory(name: str) -> list[TaskHook]:
320 return [
321 TaskStatsHookWithLogging(
322 name=name,
323 buffer=buffer,
324 interval=log_interval,
325 )
326 ]
327
328 return (
329 PipelineBuilder()
330 .add_source(source=source)
331 .pipe(decode, concurrency=concurrency)
332 .add_sink()
333 .build(
334 num_threads=concurrency,
335 queue_class=partial( # pyre-ignore[6]
336 StatsQueueWithLogging,
337 buffer=buffer,
338 interval=log_interval,
339 ),
340 task_hook_factory=hook_factory,
341 )
342 )
343
344
345def _validate_dataset(dataset_dir: Path) -> list[Path]:
346 """Validate dataset directory and return list of video files.
347
348 Args:
349 dataset_dir: Path to the dataset directory.
350
351 Returns:
352 List of video file paths.
353
354 Raises:
355 ValueError: If the directory doesn't exist or contains no videos.
356 """
357 if not dataset_dir.exists():
358 raise ValueError(f"Dataset directory does not exist: {dataset_dir}")
359
360 video_files = list(dataset_dir.rglob("*.mp4"))
361 if not video_files:
362 raise ValueError(f"No *.mp4 files found in {dataset_dir}")
363
364 return video_files
365
366
367def setup_gc_callbacks(
368 buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry],
369) -> None:
370 """Set up garbage collection callbacks to log GC events.
371
372 Args:
373 buffer: Shared queue for collecting stats entries.
374 """
375
376 def gc_callback(phase: str, _info: dict[str, int]) -> None:
377 """Callback invoked during garbage collection phases.
378
379 Args:
380 phase: The GC phase ('start' or 'stop').
381 _info: Dictionary containing GC information (unused).
382 """
383 event_name = f"gc_{phase}"
384 entry = EventLogEntry(
385 timestamp=time.time(),
386 event_name=event_name,
387 )
388 buffer.put(entry)
389 _LG.debug("GC event logged: %s", event_name)
390
391 # Register the callback with the garbage collector
392 gc.callbacks.append(gc_callback)
393 _LG.info("Garbage collection callbacks registered")
394
395
396def main() -> None:
397 """The main entry point for the example."""
398 logging.basicConfig(
399 level=logging.INFO,
400 format="%(asctime)s [%(levelname).1s]: %(message)s",
401 )
402
403 args = parse_args()
404
405 # Validate dataset and get video files
406 video_files = _validate_dataset(args.dataset_dir)
407
408 print("\n🎬 Starting video processing pipeline")
409 print(f" Dataset: {args.dataset_dir}")
410 print(f" Videos found: {len(video_files)}")
411 print(f" Database: {args.db_path}")
412 print(f" Concurrency: {args.concurrency}")
413 print(f" Log interval: {args.log_interval}s\n")
414 print("", flush=True)
415
416 # Create shared buffer and writer
417 buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry] = Queue()
418 writer = SQLiteStatsWriter(
419 str(args.db_path),
420 buffer,
421 flush_interval=max(0.1, args.log_interval - 1),
422 )
423 writer.start()
424
425 # Set up garbage collection callbacks
426 setup_gc_callbacks(buffer)
427
428 # Build and run pipeline
429 pipeline = build_pipeline(
430 source=video_files,
431 log_interval=args.log_interval,
432 concurrency=args.concurrency,
433 buffer=buffer,
434 )
435
436 try:
437 start_time = time.monotonic()
438 with pipeline.auto_stop():
439 for _ in pipeline:
440 pass
441
442 elapsed = time.monotonic() - start_time
443 print(f"\n✅ Pipeline completed in {elapsed:.2f} seconds")
444
445 finally:
446 # Ensure all stats are flushed to database
447 writer.shutdown()
448
449 # Log stats summary
450 log_stats_summary(args.db_path)
451
452
453if __name__ == "__main__":
454 main()
API Reference¶
Functions
- build_pipeline(source: Iterable[Path], log_interval: float, concurrency: int, buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry]) Pipeline[source]¶
Build the pipeline with stats logging to a buffer.
- Parameters:
source – A data source containing video file paths.
log_interval – The interval (in seconds) the performance data is saved.
concurrency – The concurrency for video decoding.
buffer – Shared queue for collecting stats entries. This queue should be consumed by a
SQLiteStatsWriterinstance.
- Returns:
A configured Pipeline instance ready for execution.
- decode(path: Path, width: int = 128, height: int = 128) Tensor[source]¶
Decode the video from the given path with rescaling.
- Parameters:
path – The path to the video file.
width – The resolution of video after rescaling.
height – The resolution of video after rescaling.
- Returns:
Video frames in Tensor.
- Return type:
Uint8 tensor in shape of
[N, C, H, W]
Classes
- class TaskStatsHookWithLogging(name: str, buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry], interval: float = 59)[source]¶
Task hook that logs statistics to a shared buffer.
This hook collects task performance statistics and writes them to a plain Python queue.
- Parameters:
name – Name of the stage/task.
buffer – Shared queue to write stats entries. This queue is typically consumed by a separate writer (e.g.,
SQLiteStatsWriter).interval – The interval (in seconds) to report the performance stats periodically.
- async interval_stats_callback(stats: TaskPerfStats) None[source]¶
Log interval statistics to the buffer.
- class StatsQueueWithLogging(name: str, buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry], buffer_size: int = 1, interval: float = 59)[source]¶
Queue that logs statistics to a shared buffer.
This queue collects queue performance statistics and writes them to a plain Python queue.
- Parameters:
name – Name of the queue. Assigned by PipelineBuilder.
buffer – Shared queue to write stats entries. This queue is typically consumed by a separate writer (e.g.,
SQLiteStatsWriter).buffer_size – The buffer size. Assigned by PipelineBuilder.
interval – The interval (in seconds) to report the performance stats periodically.
- async interval_stats_callback(stats: QueuePerfStats) None[source]¶
Log interval statistics to the buffer.
- class SQLiteStatsWriter(db_path: str, buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry | EventLogEntry], flush_interval: float)[source]¶
Background writer thread for flushing statistics to SQLite.
This class manages a background thread that periodically flushes statistics from a shared queue to a SQLite database. It’s designed to be decoupled from the hooks and queues that populate the buffer, allowing flexibility in changing storage backends.
The writer uses a periodic flushing strategy: - Wakes up at regular intervals (configured by flush_interval) - Drains all entries from the queue - Flushes to database if any entries were collected - Repeats until shutdown
- Thread Safety:
Uses queue.Queue which provides built-in thread safety for producer-consumer patterns.
- Parameters:
db_path – Path to the SQLite database file. The database schema will be initialized if it doesn’t exist.
buffer – Shared queue that serves as the buffer for log entries. This buffer is populated by hooks/queues and consumed by this writer.
flush_interval – Duration in seconds to sleep between queue drain cycles. Lower values increase CPU usage but reduce latency.
Example
>>> from queue import Queue >>> buffer: Queue[TaskStatsLogEntry | QueueStatsLogEntry] = Queue() >>> writer = SQLiteStatsWriter("stats.db", buffer) >>> writer.start() # Start background thread >>> # ... hooks populate buffer ... >>> writer.shutdown() # Flush remaining entries and stop thread