Benchmark wav¶
This example measuers the performance of loading WAV audio.
It compares three different approaches for loading WAV files:
spdl.io.load_wav(): Fast native WAV parser optimized for simple PCM formatsspdl.io.load_audio(): General-purpose audio loader using FFmpeg backendsoundfile(libsndfile): Popular third-party audio I/O library
The benchmark suite evaluates performance across multiple dimensions:
Various audio configurations (sample rates, channels, bit depths, durations)
Different thread counts (1, 2, 4, 8, 16) to measure parallel scaling
Statistical analysis with 95% confidence intervals using Student’s t-distribution
Queries per second (QPS) as the primary performance metric
Example
$ numactl --membind 0 --cpubind 0 python benchmark_wav.py --output wav_benchmark_results.csv
# Plot results
$ python plot_wav_benchmark.py --input wav_benchmark_results.csv --output wav_benchmark_plot.png
# Plot results without load_wav
$ python plot_wav_benchmark.py --input wav_benchmark_results.csv --output wav_benchmark_plot_2.png --filter '3. spdl.io.load_wav'
Result
The following plot shows the QPS (measured by the number of files processed) of each functions with different audio durations.
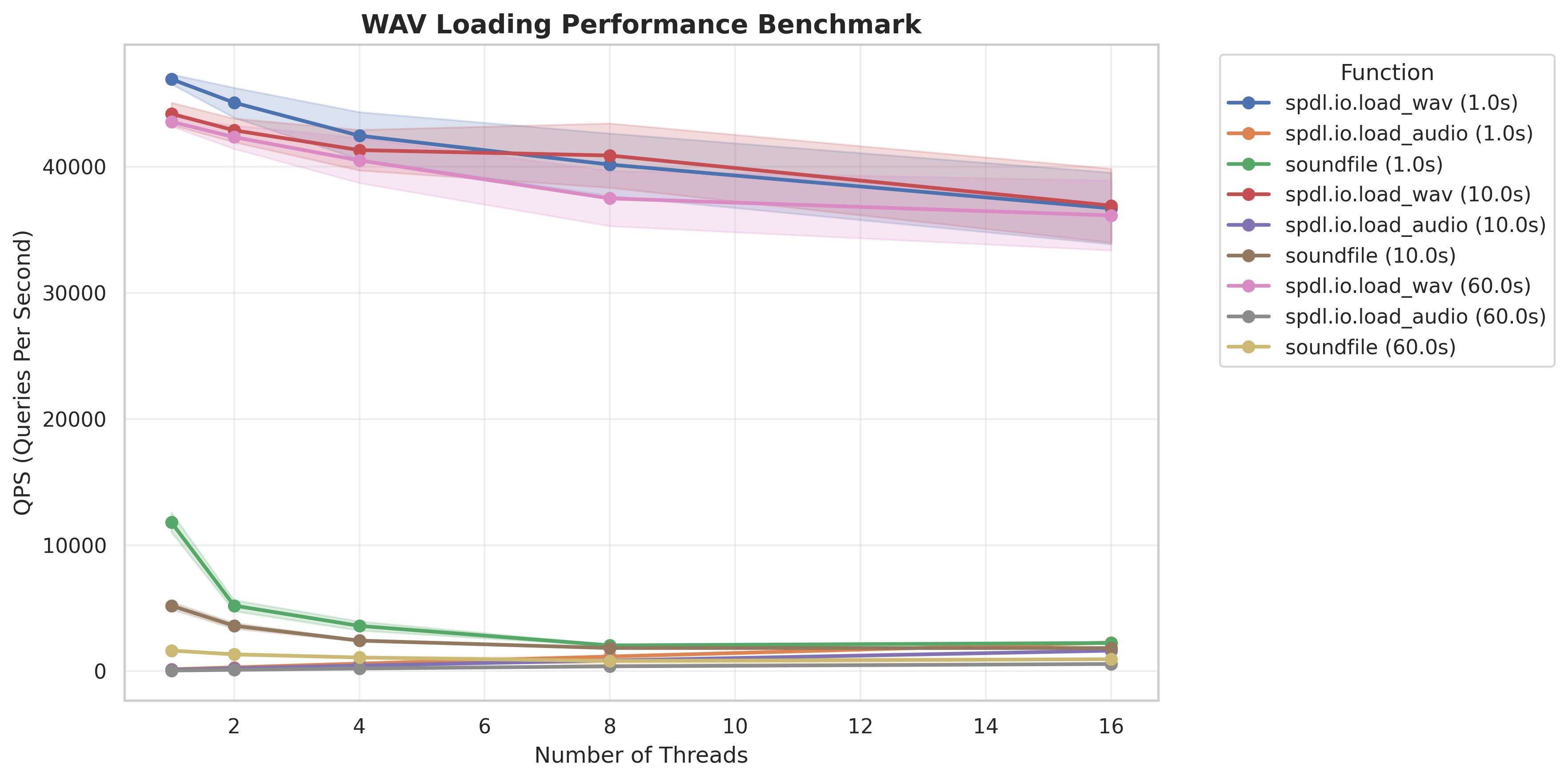
The spdl.io.load_wav() is a lot faster than the others, because all it
does is reinterpret the input byte string as array.
It shows the same performance for audio with longer duration.
And since parsing WAV is instant, the spdl.io.load_wav function spends more time on creation of NumPy Array. It needs to acquire the GIL, thus the performance does not scale in multi-threading. (This performance pattern of this function is pretty same as the spdl.io.load_npz.)
The following is the same plot without load_wav.
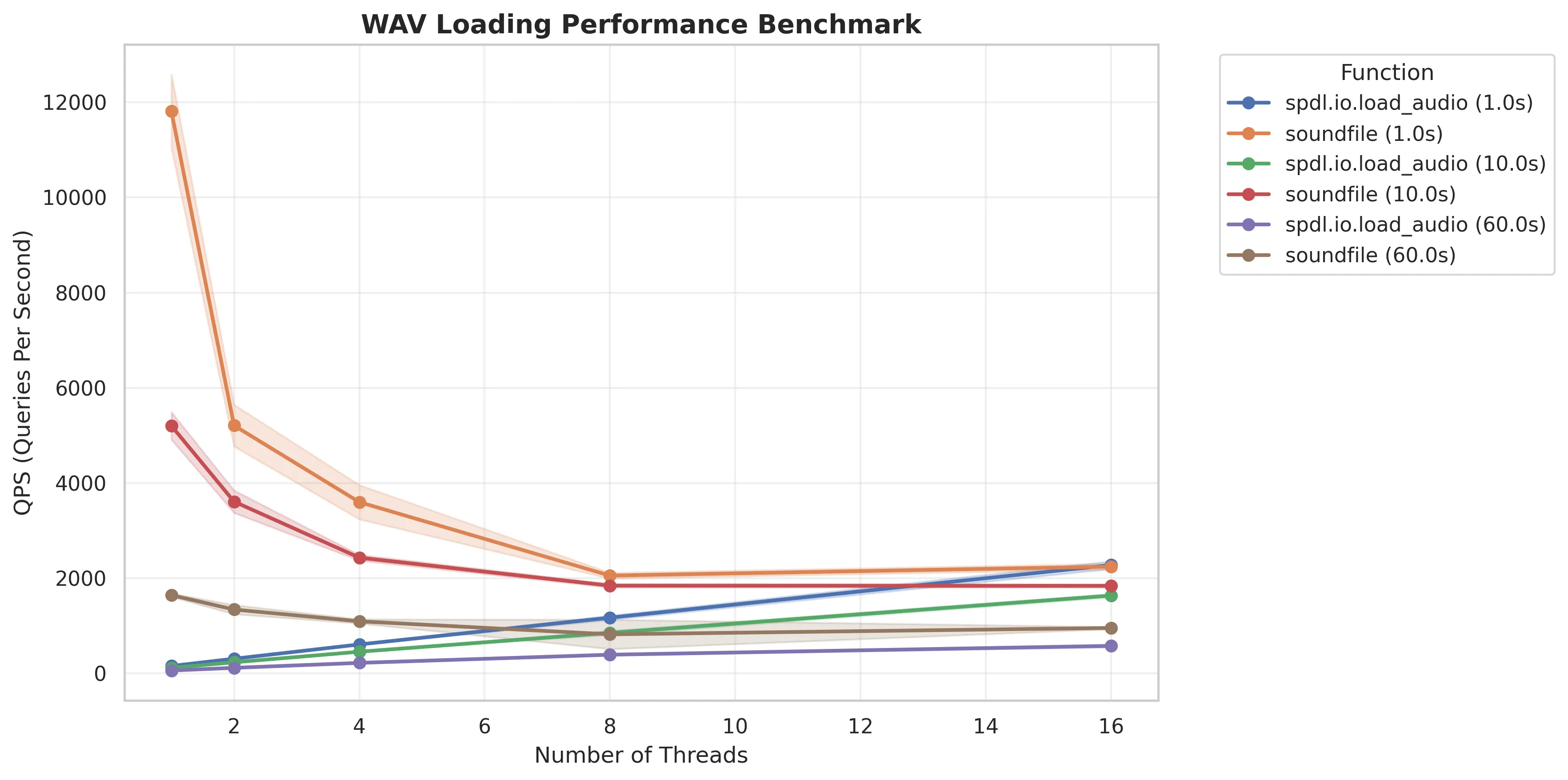
libsoundfile has to process data iteratively (using io.BytesIO) because
it does not support directly loading from byte string, so it takes longer to process
longer audio data.
The performance trend (single thread being the fastest) suggests that
it does not release the GIL majority of the time.
The spdl.io.load_audio() function (the generic FFmpeg-based implementation) does
a lot of work so its overall performance is not as good,
but it scales in multi-threading as it releases the GIL almost entirely.
Source¶
Source
Click here to see the source.
1# Copyright (c) Meta Platforms, Inc. and affiliates.
2# All rights reserved.
3#
4# This source code is licensed under the BSD-style license found in the
5# LICENSE file in the root directory of this source tree.
6
7# pyre-strict
8
9"""This example measuers the performance of loading WAV audio.
10
11It compares three different approaches for loading WAV files:
12
13- :py:func:`spdl.io.load_wav`: Fast native WAV parser optimized for simple PCM formats
14- :py:func:`spdl.io.load_audio`: General-purpose audio loader using FFmpeg backend
15- ``soundfile`` (``libsndfile``): Popular third-party audio I/O library
16
17The benchmark suite evaluates performance across multiple dimensions:
18
19- Various audio configurations (sample rates, channels, bit depths, durations)
20- Different thread counts (1, 2, 4, 8, 16) to measure parallel scaling
21- Statistical analysis with 95% confidence intervals using Student's t-distribution
22- Queries per second (QPS) as the primary performance metric
23
24**Example**
25
26.. code-block:: shell
27
28 $ numactl --membind 0 --cpubind 0 python benchmark_wav.py --output wav_benchmark_results.csv
29 # Plot results
30 $ python plot_wav_benchmark.py --input wav_benchmark_results.csv --output wav_benchmark_plot.png
31 # Plot results without load_wav
32 $ python plot_wav_benchmark.py --input wav_benchmark_results.csv --output wav_benchmark_plot_2.png --filter '3. spdl.io.load_wav'
33
34**Result**
35
36The following plot shows the QPS (measured by the number of files processed) of each
37functions with different audio durations.
38
39.. image:: ../../_static/data/example-benchmark-wav.webp
40
41
42The :py:func:`spdl.io.load_wav` is a lot faster than the others, because all it
43does is reinterpret the input byte string as array.
44It shows the same performance for audio with longer duration.
45
46And since parsing WAV is instant, the spdl.io.load_wav function spends more time on
47creation of NumPy Array.
48It needs to acquire the GIL, thus the performance does not scale in multi-threading.
49(This performance pattern of this function is pretty same as the
50:ref:`spdl.io.load_npz <example-data-formats>`.)
51
52The following is the same plot without ``load_wav``.
53
54.. image:: ../../_static/data/example-benchmark-wav-2.webp
55
56``libsoundfile`` has to process data iteratively (using ``io.BytesIO``) because
57it does not support directly loading from byte string, so it takes longer to process
58longer audio data.
59The performance trend (single thread being the fastest) suggests that
60it does not release the GIL majority of the time.
61
62The :py:func:`spdl.io.load_audio` function (the generic FFmpeg-based implementation) does
63a lot of work so its overall performance is not as good,
64but it scales in multi-threading as it releases the GIL almost entirely.
65"""
66
67__all__ = [
68 "BenchmarkResult",
69 "BenchmarkConfig",
70 "create_wav_data",
71 "load_sf",
72 "load_spdl_audio",
73 "load_spdl_wav",
74 "benchmark",
75 "run_benchmark_suite",
76 "save_results_to_csv",
77 "main",
78]
79
80import argparse
81import csv
82import io
83import sys
84import time
85from collections.abc import Callable
86from concurrent.futures import as_completed, ThreadPoolExecutor
87from dataclasses import dataclass
88
89import numpy as np
90import scipy.io.wavfile
91import scipy.stats
92import soundfile as sf
93import spdl.io
94from numpy.typing import NDArray
95
96
97def _get_python_info() -> tuple[str, bool]:
98 """Get Python version and free-threaded ABI information.
99
100 Returns:
101 Tuple of (python_version, is_free_threaded)
102 """
103 python_version = (
104 f"{sys.version_info.major}.{sys.version_info.minor}.{sys.version_info.micro}"
105 )
106 # Check if Python is running with free-threaded ABI (PEP 703)
107 # _is_gil_enabled is only available in Python 3.13+
108 try:
109 is_free_threaded = sys._is_gil_enabled() # pyre-ignore[16]
110 except AttributeError:
111 is_free_threaded = False
112 return python_version, is_free_threaded
113
114
115def create_wav_data(
116 sample_rate: int = 44100,
117 num_channels: int = 2,
118 bits_per_sample: int = 16,
119 duration_seconds: float = 1.0,
120) -> tuple[bytes, NDArray]:
121 """Create a WAV file in memory for benchmarking.
122
123 Args:
124 sample_rate: Sample rate in Hz
125 num_channels: Number of audio channels
126 bits_per_sample: Bits per sample (16 or 32)
127 duration_seconds: Duration of audio in seconds
128
129 Returns:
130 Tuple of (WAV file as bytes, audio samples array)
131 """
132 num_samples = int(sample_rate * duration_seconds)
133
134 dtype_map = {
135 16: np.int16,
136 32: np.int32,
137 }
138 dtype = dtype_map[bits_per_sample]
139 max_amplitude = 32767 if bits_per_sample == 16 else 2147483647
140
141 t = np.linspace(0, duration_seconds, num_samples)
142 frequencies = 440.0 + np.arange(num_channels) * 110.0
143 sine_waves = np.sin(2 * np.pi * frequencies[:, np.newaxis] * t)
144 samples = (sine_waves.T * max_amplitude).astype(dtype)
145
146 wav_buffer = io.BytesIO()
147 scipy.io.wavfile.write(wav_buffer, sample_rate, samples)
148 wav_data = wav_buffer.getvalue()
149
150 return wav_data, samples
151
152
153def load_sf(wav_data: bytes) -> NDArray:
154 """Load WAV data using soundfile library.
155
156 Args:
157 wav_data: WAV file data as bytes
158
159 Returns:
160 Audio samples array as int16 numpy array
161 """
162 audio_file = io.BytesIO(wav_data)
163 data, _ = sf.read(audio_file, dtype="int16")
164 return data
165
166
167def load_spdl_audio(wav_data: bytes) -> NDArray:
168 """Load WAV data using :py:func:`spdl.io.load_audio` function.
169
170 Args:
171 wav_data: WAV file data as bytes
172
173 Returns:
174 Audio samples array as numpy array
175 """
176 return spdl.io.to_numpy(spdl.io.load_audio(wav_data, filter_desc=None))
177
178
179def load_spdl_wav(wav_data: bytes) -> NDArray:
180 """Load WAV data using :py:func:`spdl.io.load_wav` function.
181
182 Args:
183 wav_data: WAV file data as bytes
184
185 Returns:
186 Audio samples array as numpy array
187 """
188 return spdl.io.to_numpy(spdl.io.load_wav(wav_data))
189
190
191@dataclass(frozen=True)
192class BenchmarkResult:
193 """Results from a single benchmark run."""
194
195 duration: float
196 qps: float
197 ci_lower: float
198 ci_upper: float
199 num_threads: int
200 function_name: str
201 duration_seconds: float
202 python_version: str
203 free_threaded: bool
204
205
206def benchmark(
207 name: str,
208 func: Callable[[], NDArray],
209 iterations: int,
210 num_threads: int,
211 num_sets: int,
212 duration_seconds: float,
213) -> tuple[BenchmarkResult, NDArray]:
214 """Benchmark a function using multiple threads and calculate statistics.
215
216 Executes a warmup phase followed by multiple benchmark sets to compute
217 performance metrics including mean queries per second (QPS) and 95%
218 confidence intervals using Student's t-distribution.
219
220 Args:
221 name: Descriptive name for the benchmark (used in results)
222 func: Callable function to benchmark (takes no args, returns NDArray)
223 iterations: Total number of function calls per benchmark set
224 num_threads: Number of concurrent threads for parallel execution
225 num_sets: Number of independent benchmark sets for confidence interval
226 duration_seconds: Duration of audio file being processed (for metadata)
227
228 Returns:
229 Tuple containing:
230 - BenchmarkResult with timing statistics, QPS, confidence intervals
231 - Output NDArray from the last function execution
232 """
233
234 with ThreadPoolExecutor(max_workers=num_threads) as executor:
235 # Warmup
236 futures = [executor.submit(func) for _ in range(num_threads * 30)]
237 for future in as_completed(futures):
238 output = future.result()
239
240 # Run multiple sets for confidence interval
241 qps_samples = []
242 for _ in range(num_sets):
243 t0 = time.perf_counter()
244 futures = [executor.submit(func) for _ in range(iterations)]
245 for future in as_completed(futures):
246 output = future.result()
247 elapsed = time.perf_counter() - t0
248 qps_samples.append(iterations / elapsed)
249
250 # Calculate mean and 95% confidence interval
251 qps_mean = np.mean(qps_samples)
252 qps_std = np.std(qps_samples, ddof=1)
253 confidence_level = 0.95
254 degrees_freedom = num_sets - 1
255 confidence_interval = scipy.stats.t.interval(
256 confidence_level,
257 degrees_freedom,
258 loc=qps_mean,
259 scale=qps_std / np.sqrt(num_sets),
260 )
261
262 duration = 1.0 / qps_mean
263 python_version, free_threaded = _get_python_info()
264 result = BenchmarkResult(
265 duration=duration,
266 qps=qps_mean,
267 ci_lower=float(confidence_interval[0]),
268 ci_upper=float(confidence_interval[1]),
269 num_threads=num_threads,
270 function_name=name,
271 duration_seconds=duration_seconds,
272 python_version=python_version,
273 free_threaded=free_threaded,
274 )
275 return result, output # pyre-ignore[61]
276
277
278def run_benchmark_suite(
279 wav_data: bytes,
280 ref: NDArray,
281 num_threads: int,
282 duration_seconds: float,
283) -> tuple[BenchmarkResult, BenchmarkResult, BenchmarkResult]:
284 """Run benchmarks for both libraries with given parameters.
285
286 Args:
287 wav_data: WAV file data as bytes
288 ref: Reference audio array for validation
289 num_threads: Number of threads (use 1 for single-threaded)
290 duration_seconds: Duration of audio in seconds
291
292 Returns:
293 Tuple of (spdl_wav_result, spdl_audio_result, soundfile_result)
294 """
295 # load_wav is fast but the performance is unstable, so we need to run more
296 iterations = 100 * num_threads
297 num_sets = 100
298
299 spdl_wav_result, output = benchmark(
300 name="3. spdl.io.load_wav",
301 func=lambda: load_spdl_wav(wav_data),
302 iterations=iterations,
303 num_threads=num_threads,
304 num_sets=num_sets,
305 duration_seconds=duration_seconds,
306 )
307 np.testing.assert_array_equal(output, ref)
308
309 # others are slow but the performance is stable.
310 iterations = 10 * num_threads
311 num_sets = 5
312
313 spdl_audio_result, output = benchmark(
314 name="2. spdl.io.load_audio",
315 func=lambda: load_spdl_audio(wav_data),
316 iterations=iterations,
317 num_threads=num_threads,
318 num_sets=num_sets,
319 duration_seconds=duration_seconds,
320 )
321 np.testing.assert_array_equal(output, ref)
322 soundfile_result, output = benchmark(
323 name="1. soundfile",
324 func=lambda: load_sf(wav_data),
325 iterations=iterations,
326 num_threads=num_threads,
327 num_sets=num_sets,
328 duration_seconds=duration_seconds,
329 )
330 if output.ndim == 1:
331 output = output[:, None]
332 np.testing.assert_array_equal(output, ref)
333
334 return spdl_wav_result, spdl_audio_result, soundfile_result
335
336
337@dataclass(frozen=True)
338class BenchmarkConfig:
339 """Configuration for audio file parameters used in benchmarking.
340
341 Attributes:
342 sample_rate: Audio sample rate in Hz (e.g., 44100 for CD quality)
343 num_channels: Number of audio channels (1=mono, 2=stereo, etc.)
344 bits_per_sample: Bit depth per sample (16 or 32)
345 duration_seconds: Duration of the audio file in seconds
346 """
347
348 sample_rate: int
349 num_channels: int
350 bits_per_sample: int
351 duration_seconds: float
352
353
354def save_results_to_csv(
355 results: list[BenchmarkResult], output_file: str = "benchmark_results.csv"
356) -> None:
357 """Save benchmark results to a CSV file that Excel can open.
358
359 Args:
360 results: List of BenchmarkResult objects containing benchmark data
361 output_file: Output file path for the CSV file
362 """
363 with open(output_file, "w", newline="") as csvfile:
364 fieldnames = [
365 "function_name",
366 "duration_seconds",
367 "num_threads",
368 "qps",
369 "ci_lower",
370 "ci_upper",
371 "duration",
372 "python_version",
373 "free_threaded",
374 ]
375 writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
376
377 writer.writeheader()
378 for r in results:
379 writer.writerow(
380 {
381 "function_name": r.function_name,
382 "duration_seconds": r.duration_seconds,
383 "num_threads": r.num_threads,
384 "qps": r.qps,
385 "ci_lower": r.ci_lower,
386 "ci_upper": r.ci_upper,
387 "duration": r.duration,
388 "python_version": r.python_version,
389 "free_threaded": r.free_threaded,
390 }
391 )
392 print(f"Results saved to {output_file}")
393
394
395def _parse_args() -> argparse.Namespace:
396 """Parse command line arguments for the benchmark script.
397
398 Returns:
399 Parsed command line arguments
400 """
401 parser = argparse.ArgumentParser(description="Benchmark WAV loading performance")
402 parser.add_argument(
403 "--output",
404 type=str,
405 default="wav_benchmark_results.csv",
406 help="Output file path.",
407 )
408 return parser.parse_args()
409
410
411def main() -> None:
412 """Run comprehensive benchmark suite for WAV loading performance.
413
414 Benchmarks multiple configurations of audio files with different durations,
415 comparing spdl.io.load_wav, spdl.io.load_audio, and soundfile libraries
416 across various thread counts (1, 2, 4, 8, 16).
417 """
418 args = _parse_args()
419
420 benchmark_configs = [
421 # (sample_rate, num_channels, bits_per_sample, duration_seconds, iterations)
422 # BenchmarkConfig(8000, 1, 16, 1.0), # Low quality mono
423 # BenchmarkConfig(16000, 1, 16, 1.0), # Speech quality mono
424 # BenchmarkConfig(48000, 2, 16, 1.0), # High quality stereo
425 # BenchmarkConfig(48000, 8, 16, 1.0), # Multi-channel audio
426 BenchmarkConfig(44100, 2, 16, 1.0), # CD quality stereo
427 BenchmarkConfig(44100, 2, 16, 10.0), #
428 BenchmarkConfig(44100, 2, 16, 60.0), #
429 # (44100, 2, 24, 1.0, 100), # 24-bit audio
430 ]
431
432 results: list[BenchmarkResult] = []
433
434 for cfg in benchmark_configs:
435 print(cfg)
436 wav_data, ref = create_wav_data(
437 sample_rate=cfg.sample_rate,
438 num_channels=cfg.num_channels,
439 bits_per_sample=cfg.bits_per_sample,
440 duration_seconds=cfg.duration_seconds,
441 )
442 print(
443 f"Threads,"
444 f"SPDL WAV QPS ({cfg.duration_seconds} sec),CI Lower, CI Upper,"
445 f"SPDL Audio QPS ({cfg.duration_seconds} sec),CI Lower, CI Upper,"
446 f"soundfile QPS ({cfg.duration_seconds} sec),CI Lower, CI Upper"
447 )
448 for num_threads in [1, 2, 4, 8, 16]:
449 spdl_wav_result, spdl_audio_result, soundfile_result = run_benchmark_suite(
450 wav_data,
451 ref,
452 num_threads=num_threads,
453 duration_seconds=cfg.duration_seconds,
454 )
455 results.extend([spdl_wav_result, spdl_audio_result, soundfile_result])
456 print(
457 f"{num_threads},"
458 f"{spdl_wav_result.qps:.2f},{spdl_wav_result.ci_lower:.2f},{spdl_wav_result.ci_upper:.2f},"
459 f"{spdl_audio_result.qps:.2f},{spdl_audio_result.ci_lower:.2f},{spdl_audio_result.ci_upper:.2f},"
460 f"{soundfile_result.qps:.2f},{soundfile_result.ci_lower:.2f},{soundfile_result.ci_upper:.2f}"
461 )
462
463 save_results_to_csv(results, args.output)
464 print(
465 f"\nBenchmark complete. To generate plots, run:\n"
466 f"python plot_wav_benchmark.py --input {args.output} --output {args.output.replace('.csv', '.png')}"
467 )
468
469
470if __name__ == "__main__":
471 main()
Functions¶
Functions
- create_wav_data(sample_rate: int = 44100, num_channels: int = 2, bits_per_sample: int = 16, duration_seconds: float = 1.0) tuple[bytes, ndarray[tuple[Any, ...], dtype[_ScalarT]]][source]¶
Create a WAV file in memory for benchmarking.
- Parameters:
sample_rate – Sample rate in Hz
num_channels – Number of audio channels
bits_per_sample – Bits per sample (16 or 32)
duration_seconds – Duration of audio in seconds
- Returns:
Tuple of (WAV file as bytes, audio samples array)
- load_sf(wav_data: bytes) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]¶
Load WAV data using soundfile library.
- Parameters:
wav_data – WAV file data as bytes
- Returns:
Audio samples array as int16 numpy array
- load_spdl_audio(wav_data: bytes) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]¶
Load WAV data using
spdl.io.load_audio()function.- Parameters:
wav_data – WAV file data as bytes
- Returns:
Audio samples array as numpy array
- load_spdl_wav(wav_data: bytes) ndarray[tuple[Any, ...], dtype[_ScalarT]][source]¶
Load WAV data using
spdl.io.load_wav()function.- Parameters:
wav_data – WAV file data as bytes
- Returns:
Audio samples array as numpy array
- benchmark(name: str, func: Callable[[], ndarray[tuple[Any, ...], dtype[_ScalarT]]], iterations: int, num_threads: int, num_sets: int, duration_seconds: float) tuple[BenchmarkResult, ndarray[tuple[Any, ...], dtype[_ScalarT]]][source]¶
Benchmark a function using multiple threads and calculate statistics.
Executes a warmup phase followed by multiple benchmark sets to compute performance metrics including mean queries per second (QPS) and 95% confidence intervals using Student’s t-distribution.
- Parameters:
name – Descriptive name for the benchmark (used in results)
func – Callable function to benchmark (takes no args, returns NDArray)
iterations – Total number of function calls per benchmark set
num_threads – Number of concurrent threads for parallel execution
num_sets – Number of independent benchmark sets for confidence interval
duration_seconds – Duration of audio file being processed (for metadata)
- Returns:
BenchmarkResult with timing statistics, QPS, confidence intervals
Output NDArray from the last function execution
- Return type:
Tuple containing
- run_benchmark_suite(wav_data: bytes, ref: ndarray[tuple[Any, ...], dtype[_ScalarT]], num_threads: int, duration_seconds: float) tuple[BenchmarkResult, BenchmarkResult, BenchmarkResult][source]¶
Run benchmarks for both libraries with given parameters.
- Parameters:
wav_data – WAV file data as bytes
ref – Reference audio array for validation
num_threads – Number of threads (use 1 for single-threaded)
duration_seconds – Duration of audio in seconds
- Returns:
Tuple of (spdl_wav_result, spdl_audio_result, soundfile_result)
Classes¶
Classes
- class BenchmarkResult(duration: float, qps: float, ci_lower: float, ci_upper: float, num_threads: int, function_name: str, duration_seconds: float, python_version: str, free_threaded: bool)[source]¶
Results from a single benchmark run.