|
Tensor Comprehensions
|
|
Tensor Comprehensions
|
#include <compilation_cache.h>
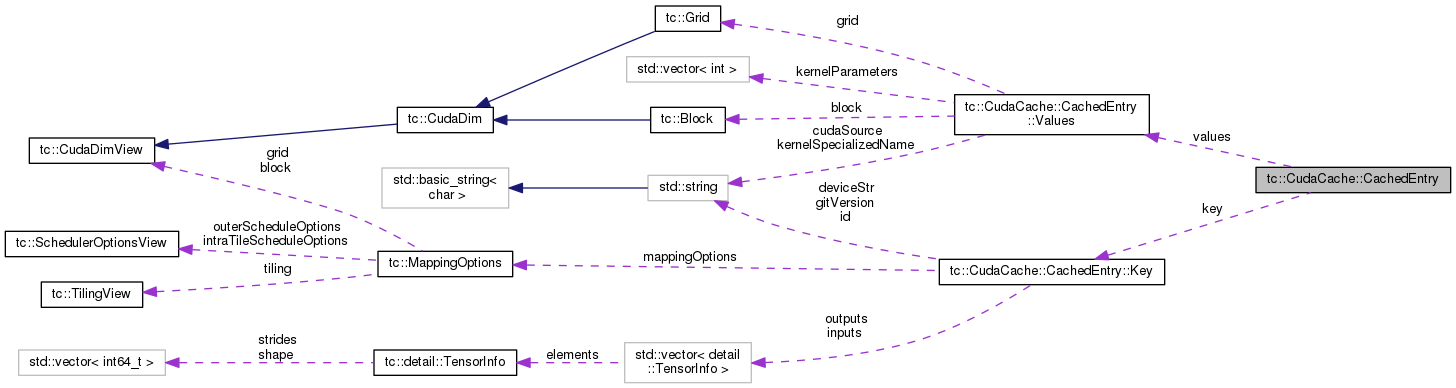
Classes | |
| struct | Key |
| struct | Values |
Public Member Functions | |
| CachedEntry (const std::string &id, const std::string &kernelSpecializedName, const std::vector< int > &kernelParameters, const Grid &grid, const Block &block, const MappingOptions &mappingOptions, const std::vector< const DLTensor * > &inputs, const std::vector< const DLTensor * > &outputs, const std::string &cudaSource, const std::string &deviceStr) | |
| CachedEntry (const CudaCacheEntryProto &buf) | |
| CudaCacheEntryProto | toProtobuf () const |
Public Attributes | |
| Key | key |
| Values | values |
A CudaCache holds multiple CachedEntry's. Each CachedEntry is split to two conceptual parts the key and the values. The values are: the specialized (wrt inputs) Cuda source code, the kernel's specialized name, the kernel parameters, the Cuda block and grid dimensions The key is: the kernel/op's unique id (string), the specialized input dimensions, the isl options when the kernel was optimized, the target architecture (string), tc's version (string),
| tc::CudaCache::CachedEntry::CachedEntry | ( | const std::string & | id, |
| const std::string & | kernelSpecializedName, | ||
| const std::vector< int > & | kernelParameters, | ||
| const Grid & | grid, | ||
| const Block & | block, | ||
| const MappingOptions & | mappingOptions, | ||
| const std::vector< const DLTensor * > & | inputs, | ||
| const std::vector< const DLTensor * > & | outputs, | ||
| const std::string & | cudaSource, | ||
| const std::string & | deviceStr | ||
| ) |
| tc::CudaCache::CachedEntry::CachedEntry | ( | const CudaCacheEntryProto & | buf | ) |
| CudaCacheEntryProto tc::CudaCache::CachedEntry::toProtobuf | ( | ) | const |
| Key tc::CudaCache::CachedEntry::key |
| Values tc::CudaCache::CachedEntry::values |
 1.8.5
1.8.5 
