|
Tensor Comprehensions
|
|
Tensor Comprehensions
|
#include <execution_engine.h>
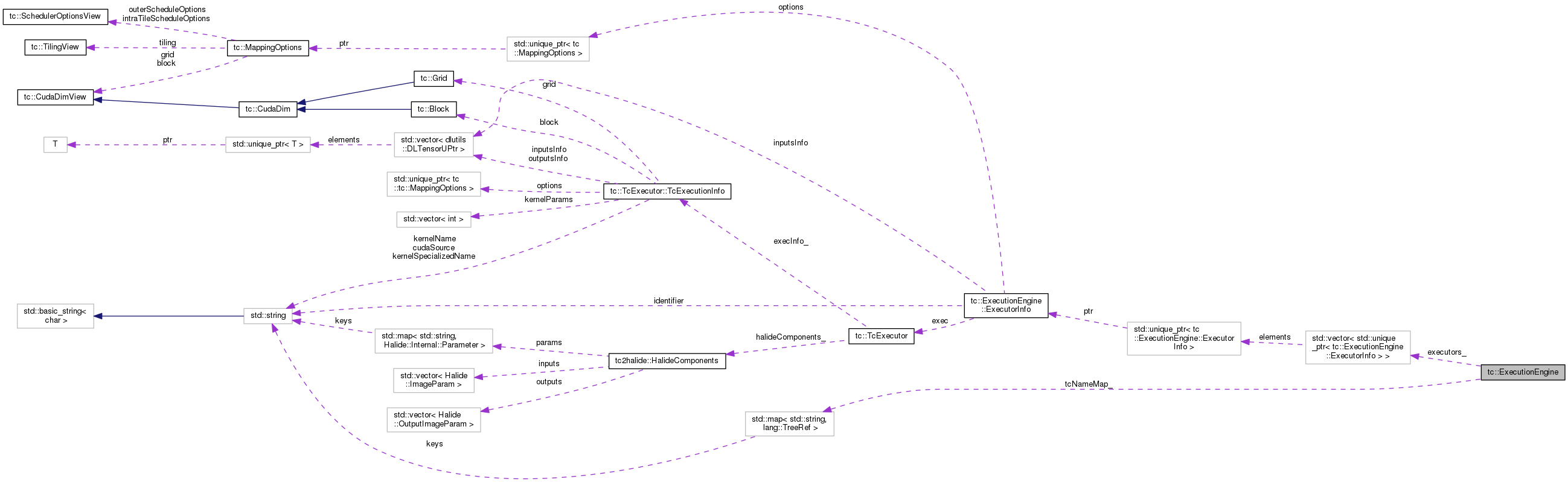
Classes | |
| struct | ExecutorInfo |
Public Member Functions | |
| ExecutionEngine ()=default | |
| void | define (const std::string &language) |
| void | define (const std::vector< lang::TreeRef > &treeRefs) |
| void | addTC (const std::string &tc) |
| std::vector< const DLTensor * > | inferOutputTensorInfo (const std::string &name, const std::vector< const DLTensor * > &inTensorPtrs) |
| lang::TreeRef | treeForFunction (const std::string &name) |
| size_t | compile (const std::string &name, const std::vector< const DLTensor * > &inputs, const MappingOptions &options) |
| Returns a handle for the compiled kernel. More... | |
| Duration | run (size_t handle, const std::vector< const DLTensor * > &inputs, const std::vector< DLTensor * > &outputs, bool profile=false, std::function< bool(const ExecutorInfo *)> pruningFunction=[](const ExecutorInfo *){return false;}) |
| void | uncheckedRun (size_t handle, const std::vector< const void * > &inputs, const std::vector< void * > &outputs) |
| void | clear (size_t handle) |
Private Member Functions | |
| size_t | getHandle (const std::string &name, const std::vector< const DLTensor * > &inputsInfo, const MappingOptions &options) |
| std::unique_ptr< ExecutorInfo > | makeExecutorInfo (const std::string &name, const std::vector< const DLTensor * > &inputsInfo, const MappingOptions &options) |
| size_t | emplaceExecutor (std::unique_ptr< ExecutorInfo > p) |
Private Attributes | |
| std::mutex | executorInfoMutex |
| For thread-safety perform all cheap operations under lock. More... | |
| std::vector< std::unique_ptr < ExecutorInfo > > | executors_ |
| std::map< std::string, lang::TreeRef > | tcNameMap_ |
| size_t | uidCounter = 0 |
The goal for this new shiny API is to provide a different pathway for being able to execute the kernels for multiple TC i.e. given the language which can have multiple TCs, people should be able to run things by just calling out the run function with the name of function and the inputs to run on.
|
default |
| void tc::ExecutionEngine::addTC | ( | const std::string & | tc | ) |
| void tc::ExecutionEngine::clear | ( | size_t | handle | ) |
| size_t tc::ExecutionEngine::compile | ( | const std::string & | name, |
| const std::vector< const DLTensor * > & | inputs, | ||
| const MappingOptions & | options | ||
| ) |
Returns a handle for the compiled kernel.
| void tc::ExecutionEngine::define | ( | const std::string & | language | ) |
Create the ExecutionEngine::tcNameMap_ using the language passed to it - should support many TC.
| void tc::ExecutionEngine::define | ( | const std::vector< lang::TreeRef > & | treeRefs | ) |
Create the ExecutionEngine::tcNameMap_ from the parsed TC string - supports many TC.
|
private |
|
private |
| std::vector<const DLTensor*> tc::ExecutionEngine::inferOutputTensorInfo | ( | const std::string & | name, |
| const std::vector< const DLTensor * > & | inTensorPtrs | ||
| ) |
Get the output Tensor info that can be used by the calling framework to allocate storage for the output.
|
private |
| Duration tc::ExecutionEngine::run | ( | size_t | handle, |
| const std::vector< const DLTensor * > & | inputs, | ||
| const std::vector< DLTensor * > & | outputs, | ||
| bool | profile = false, |
||
| std::function< bool(const ExecutorInfo *)> | pruningFunction = [](const ExecutorInfo *){return false;} |
||
| ) |
Run a TC specified by its name on the given tensor inputs and fill the outputs with the result. The TC is looked up by its handle. If profile is set, the kernel runtime is returned.
The pruning function returns true if the run should not proceed (e.g. if there are too few threads mapped that would likely result in catastrophic performance). In this case, return Duration::max().
|
inline |
| void tc::ExecutionEngine::uncheckedRun | ( | size_t | handle, |
| const std::vector< const void * > & | inputs, | ||
| const std::vector< void * > & | outputs | ||
| ) |
This is the "low-latency" mode in which we just propagate raw pointers to data in GPU address space. No tensor-related information can be checked so it is the user's responsibility to ensure that shapes and strides match. If the user doesn't then segfault will likely occur.
|
private |
For thread-safety perform all cheap operations under lock.
|
private |
|
private |
|
private |
 1.8.5
1.8.5 
