Leveraging Demonstrations with Latent Space Priors
Transactions on Machine Learning Research (03/2023)
TL;DR Combining skill learning from demonstrations and sequence modeling to accelerate learning on transfer tasks.
Paper | Videos | Code | Pre-Trained Models
Abstract Demonstrations provide insight into relevant state or action space regions, bearing great potential to boost the efficiency and practicality of reinforcement learning agents. In this work, we propose to leverage demonstration datasets by combining skill learning and sequence modeling. Starting with a learned joint latent space, we separately train a generative model of demonstration sequences and an accompanying low-level policy. The sequence model forms a latent space prior over plausible demonstration behaviors to accelerate learning of high-level policies. We show how to acquire such priors from state-only motion capture demonstrations and explore several methods for integrating them into policy learning on transfer tasks. Our experimental results confirm that latent space priors provide significant gains in learning speed and final performance. We benchmark our approach on a set of challenging sparse-reward environments with a complex, simulated humanoid, and on offline RL benchmarks for navigation and object manipulation.
Approach
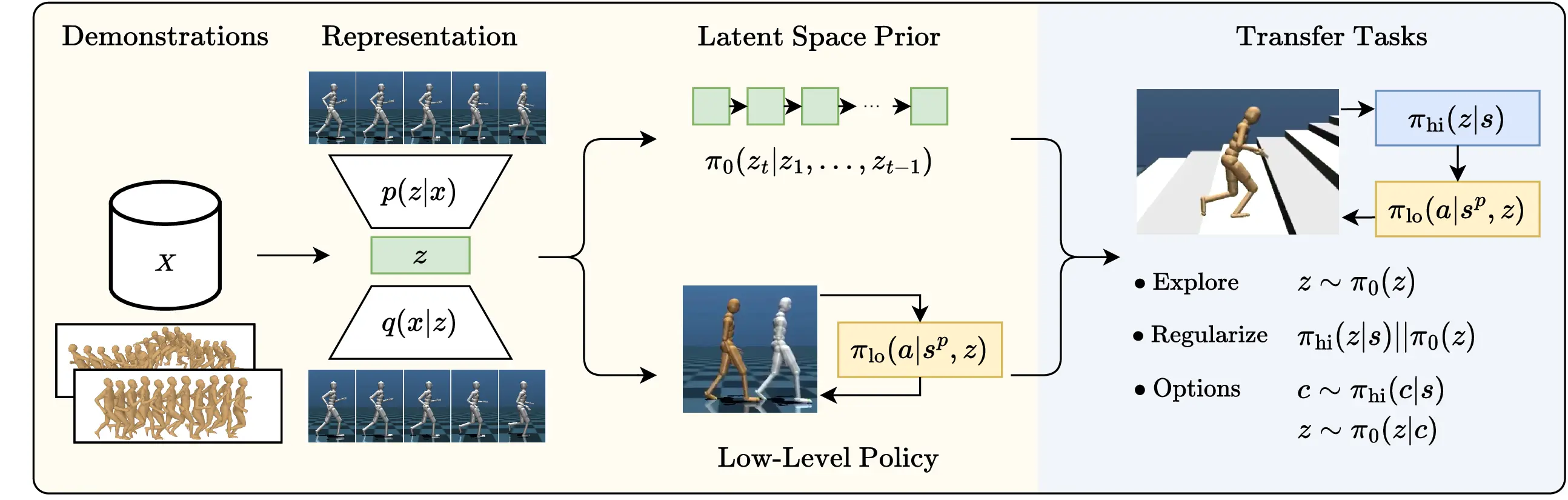
Our approach consists of a pre-training phase (left), followed by high-level
policy learning on transfer tasks. For pre-training, we embed
demonstration trajectories \( \boldsymbol{x} \in X \) into a latent representations
\( z \) with an auto-encoder. We separately learn a prior \( \pi_0 \) that models
latent space trajectories, as well as a low-level policy \( \pi_{lo} \) trained to
reenact demonstrations from proprioceptive observations \( s^p \) a near-term
targets \( z \). On downstream tasks, we train a high-level policy \( \pi_{hi}(z|s) \)
and utilize the latent space prior \( \pi_0 \) to accelerate learning.
We investigate several methods of integration: (1) augmenting the exploration
policy with sequences sampled from the prior; (2) regularizing the policy
towards distributions predicted by the prior; (3) conditionally generating
sequences from high-level actions actions to provide temporal abstraction.
Videos
Pre-Training:
Low-level Policy |
Sampled Motions (kinematic control) |
Sampled Motions (physics-based control)
Transfer Tasks:
GoToTargets |
Gaps |
Butterflies |
Stairs |
Planning
Offline RL Tasks:
AntMaze |
FankaKitchen
Low-Level Policy
We show our low-level policy reenacting random clips from the demonstration dataset of motion capture clips. The low-level policy controls the golden robot, the demonstration poses are shown in silver.
Sampled Motions (kinematic control)
We sample five latent state sequences from the prior, without providing an initial context, and decode them into poses with the VAE decoder. The sampled motions contain sequences from several different demonstrations clips; for example, the leftmost clip starts with Subject 77, Trial 10 and transitions into punches from the end of Subject 86, Trial 1. Overall, motions are of good quality, but we sometimes notice unrealistic behavior, e.g., the character sliding over the floor or jumping too far.
Sampled Motions (physics-based control)
Here, the sampled motions from above are re-enacted with the trained low-level policy by conditioning on the respective latent state sequence.
GoToTargets
- The policy without a prior (left) prefers leftward turns, even if this results in larger turns than necessary.
- For "z-prior Exploration", the robot slips after attempting a sharp turn at high speed. This is a common failure mode in the GoToTargets task.
- "z-prior Regularize" exhibits fast movements and quick turns.
- Using priors as options results in smoother movements at the expense of slower turns.
- The CoMic policy begins to slip continuously later in training, which leads to a drop in performance.
Gaps
- With priors as options, the humanoid utilizes its arms in a natural manner.
- Other variants using our low-level policy achieve high running speeds and perform quick, small steps when necessary.
- The CoMic policy runs at a lower speed and achieves lower returns.
Butterflies
- All policies exhibit a rather unnatural walking style, as this task focuses on arm and hand movements.
- Rollouts for "z-prior Explore" and "z-prior Regularize" achieve the maximum return of 10.
Stairs
- All policies have trouble descending the staircase, with "z-prior Options" falling only after completing it.
- Policies using the prior as options occasionally reach the second staircase in other task instances (not shown).
- The CoMic low-level policy fails to climb stairs.
Planning
Rollouts planning with latent space priors on a single-goal navigation task. We also visualize the results from every 4th planning step below each video. The black dot marks the agent position, the goal is shown in blue. Orange lines depict the actual (future) trajectory of the robot, the selected plan is highlighted in red. A sample of other candidate plans is shown in grey. Note that plans (decoded latent state priors) contain full pose information; we show the X/Y positions only here.
AntMaze
For AntMaze, we pre-train low-level policies and latent space priors on the D4RL offline dataset and train high-level policies in a dense-reward setting. After 2M samples, all methods integrating the latent space prior solve the task. Without the prior (left), further training is required to reach the goal reliably. Videos are recorded in 2x real-time.
The low-level policy and prior obtained from the medium-sized maze above are transfer well on the larger maze. The rollouts below are again obtained after 2M samples of high-level policy learning. Without a prior, this task cannot be solved even within 10M samples.
FrankaKitchen
For the FrankaKitchen environment, low-level policies and latent space priors are trained on the corresponding D4RL offline dataset. A challenge in this environment is sensor noise applied to observations. Using the prior for temporaly abstraction is the only method that can achieve the maximum return. Both the exploration and the regularization approach do not provide significant benefits over not using the prior.