Hierarchical Skills for Efficient Exploration
NeurIPS 2021
TL;DR Pre-training a hierarchy of skill policies and using them effectively on sparse-reward downstream tasks.
Paper | Talk | Videos | Code | Pre-Trained Skill Policies | Benchmark
Abstract In reinforcement learning, pre-trained low-level skills have the potential to greatly facilitate exploration. However, prior knowledge of the downstream task is required to strike the right balance between generality (fine-grained control) and specificity (faster learning) in skill design. In previous work on continuous control, the sensitivity of methods to this trade-off has not been addressed explicitly, as locomotion provides a suitable prior for navigation tasks, which have been of foremost interest. In this work, we analyze this trade-off for low-level policy pre-training with a new benchmark suite of diverse, sparse-reward tasks for bipedal robots. We alleviate the need for prior knowledge by proposing a hierarchical skill learning framework that acquires skills of varying complexity in an unsupervised manner. For utilization on downstream tasks, we present a three-layered hierarchical learning algorithm to automatically trade off between general and specific skills as required by the respective task. In our experiments, we show that our approach performs this trade-off effectively and achieves better results than current state-of-the-art methods for end-to-end hierarchical reinforcement learning and unsupervised skill discovery.
Approach
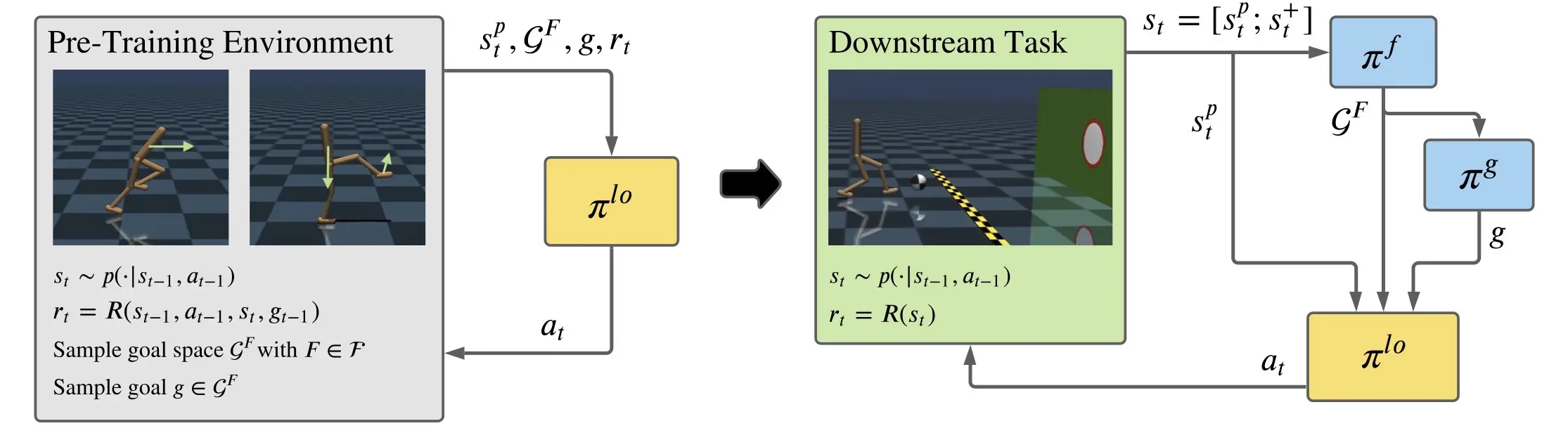
| Low-level policies are learned in an empty pre-training environment, with the objective to reach random configurations (goal g) of a sampled skill (goal space GF defined over a feature set F). Examples of goal space features are translation along the X-axis or the position of a limb. | Learning on downstream tasks with a three-level hierarchical policy to select a goal space, a goal and finally a native action at with the pre-trained low-level policy. The low-level policy acts on proprioceptive states sp, while high-level policies πf and πg leverage extra task-specific information via s+. |
Pre-Training We pre-train a shared skill policy to achieve goals in a hierarchy of goal spaces that encompasses both single features (left) and their combinations (middle). In the empty pre-training environment, goal spaces and goals are sampled randomly (right).
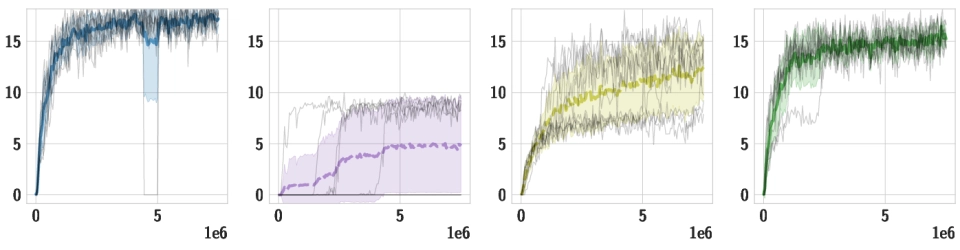
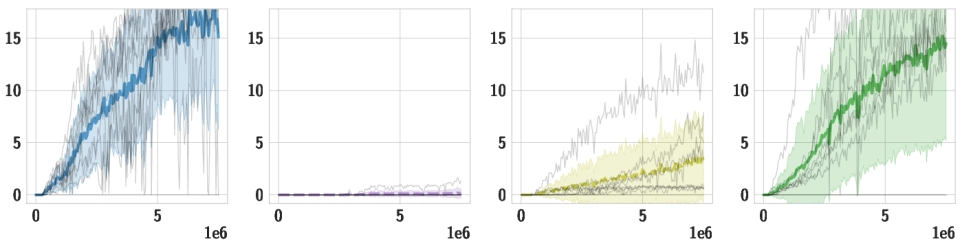
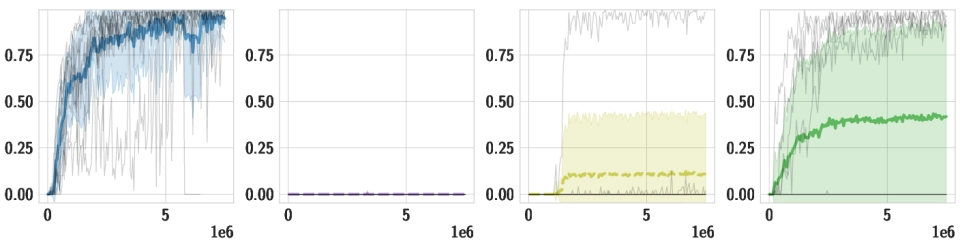
Downstream Tasks We use the same pre-trained policy for all downstream tasks, and train individual high-level policies on top of it. Below, we should videos of the best training runs for both HSD-3 and selected baselines. For SAC in particular, only very few (if any) out of 9 seeds make meaningful progress on tasks with a sparse reward. Click the chart icon on the right to gauge learning speed and robustness across seeds.
| Environment |
HSD-3
Our proposed algorithm
|
SAC
Soft Actor-Critic
|
DIAYN-C
Skills acquired with a variant of
"Diversity is all you need"
|
SD
Our pre-trained skill policy, using
the full goal space
|
|
|---|---|---|---|---|---|
| Stairs |
|
|
|||
| Gaps |
|
|
|||
| GoalWall |
|
|
|||
| Hurdles |
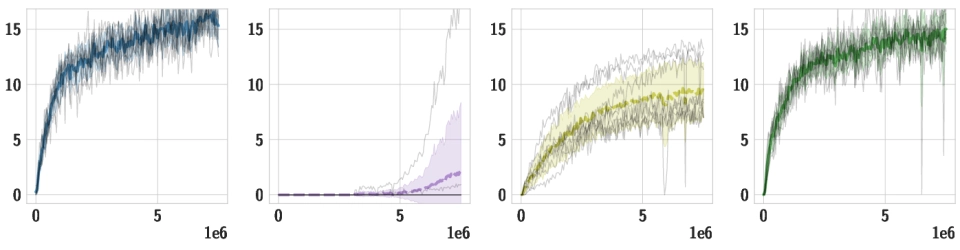
|
|
|||
| Limbo |
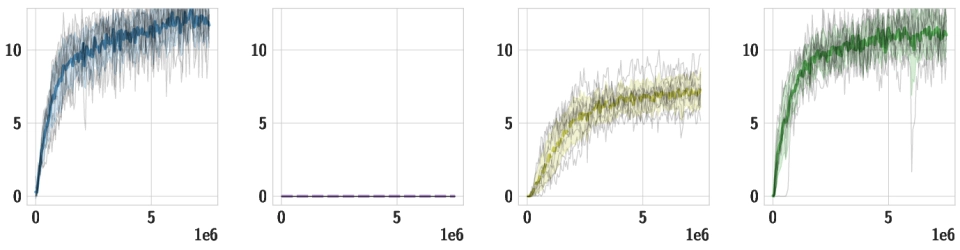
|
|
|||
| HurdlesLimbo |
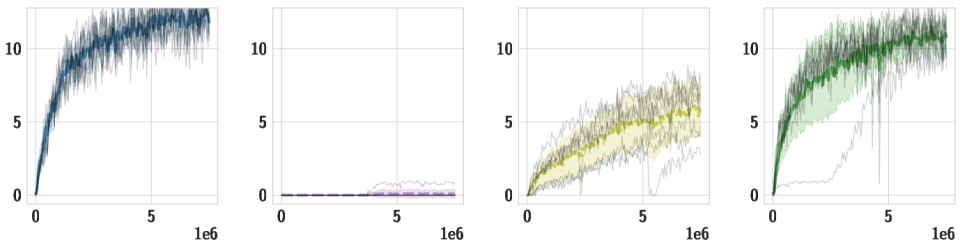
|
|
|||
| PoleBalance |
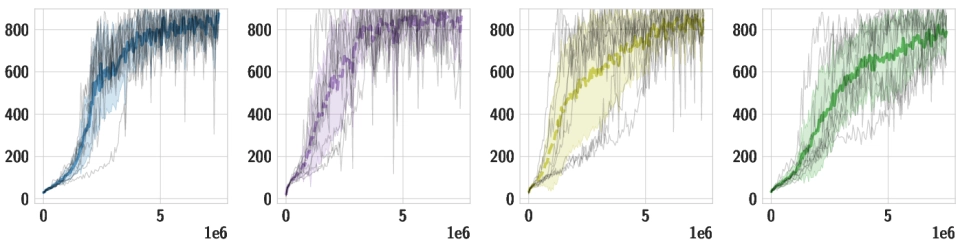
|
|
|||
| Environment |
HSD-3
Our proposed algorithm
|
SAC
Soft Actor-Critic
|
SD
Our pre-trained skill policy, using
the full goal space
|
SD*
Our pre-trained skill policy, using the best single goal space
|
|
|---|---|---|---|---|---|
| Stairs |
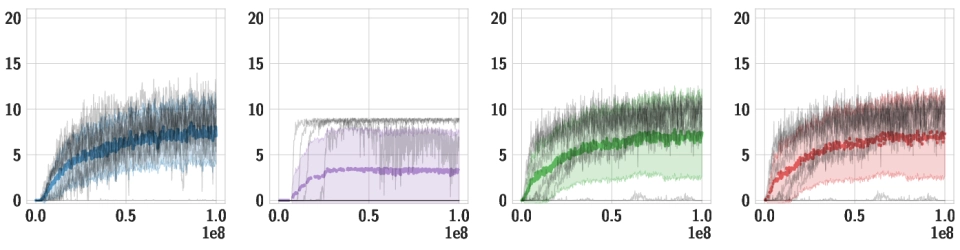
|
|
|||
| Hurdles |
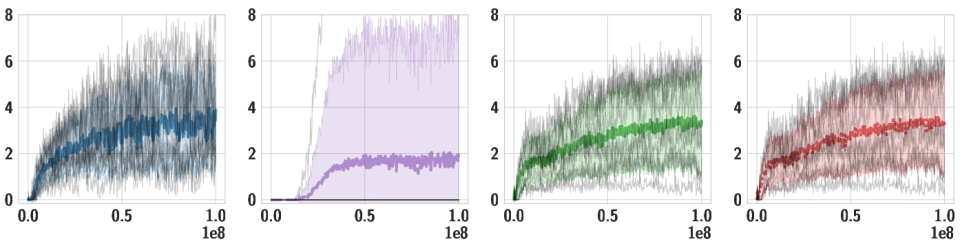
|
|
|||
| Limbo |
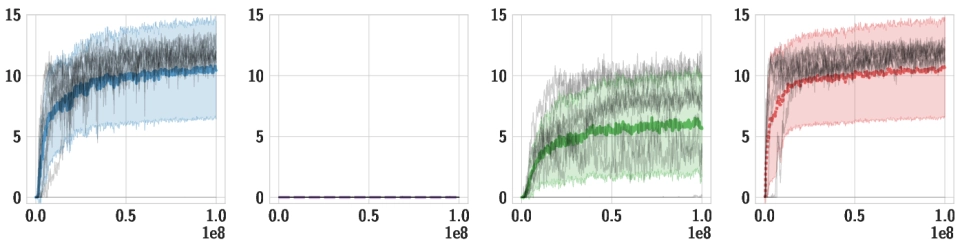
|
|
|||
| HurdlesLimbo |
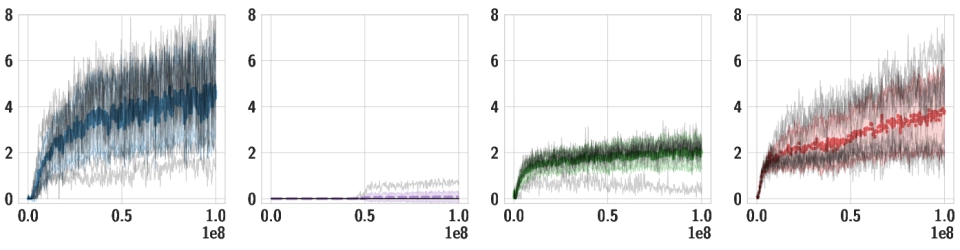
|
|
|||
| PoleBalance |
|
|
|||