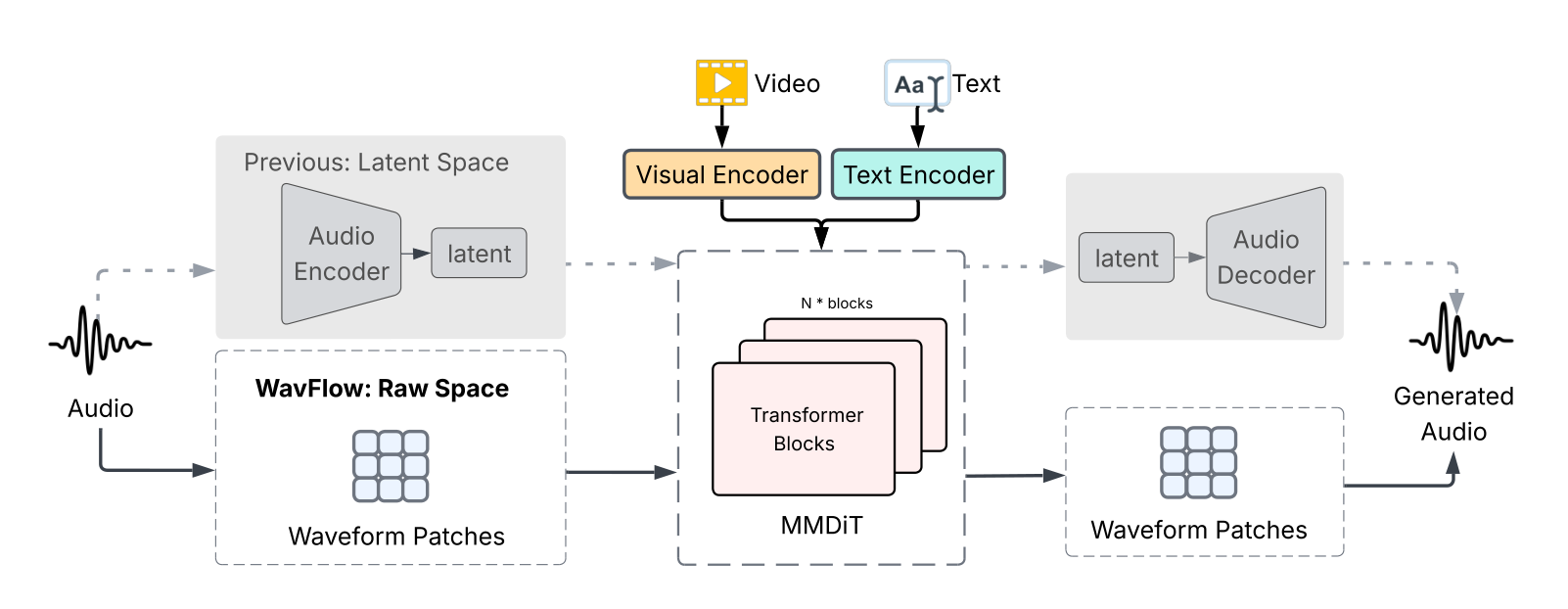
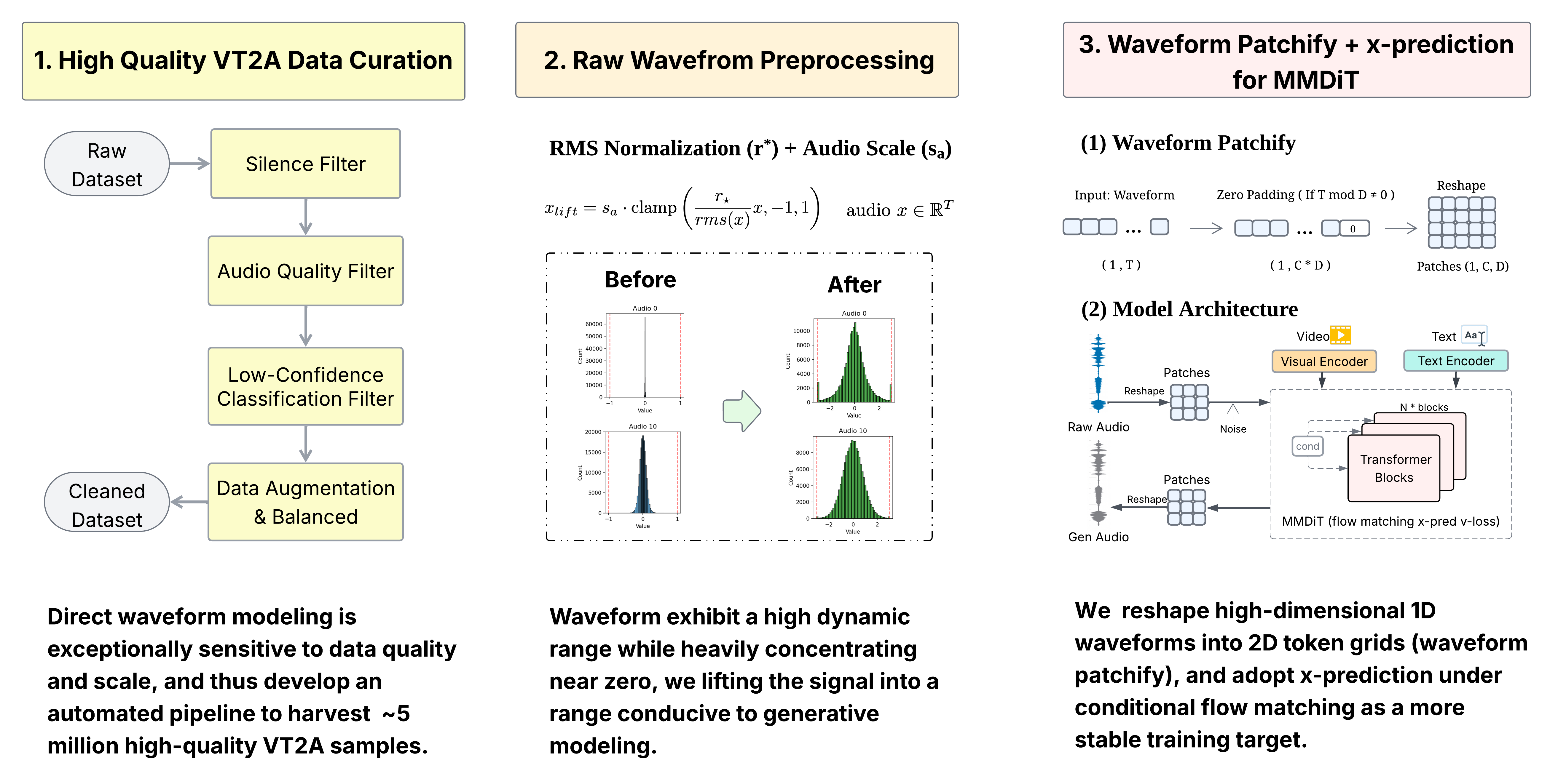
WavFlow: Audio Generation in
Waveform Space
High-fidelity audio synthesized directly in raw waveform space — no VAE, no latent compression.
1 Meta AI
 2 Northeastern University
2 Northeastern University

2 Northeastern University