Paper
Cycle Consistency for Robust Visual Question Answering
Meet Shah, Xinlei Chen, Marcus Rohrbach, Devi Parikh
CVPR 2019 (Oral)
Despite significant progress in Visual Question Answering over the years, robustness of today's VQA models leave much to be desired. We introduce a new evaluation protocol and associated dataset (VQA-Rephrasings) and show that state-of-the-art VQA models are notoriously brittle to linguistic variations in questions. VQA-Rephrasings contains 3 human-provided rephrasings for 40k questions spanning 40k images from the VQA v2.0 validation dataset.
As a step towards improving robustness of VQA models, we propose a model-agnostic framework that exploits cycle consistency. Specifically, we train a model to not only answer a question, but also generate a question conditioned on the answer, such that the answer predicted for the generated question is the same as the ground truth answer to the original question.
Without the use of additional annotations,we show that our approach is significantly more robust to linguistic variations than state-of-the-art VQA models, when evaluated on the VQA-Rephrasings dataset. In addition, our approach outperforms state-of-the-art approaches on the standard VQA and Visual Question Generation tasks on the challenging VQA v2.0 dataset.

Model
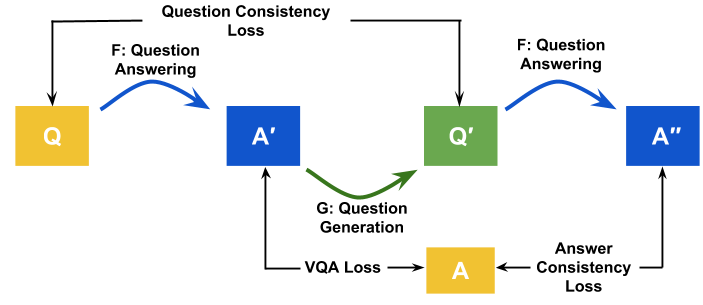
Abstract representation of the proposed cycle-consistent training scheme: Given a triplet of image \(I\), question \(Q\), and ground truth answer \(A\), a Visual Question Answering (VQA) model is a transformation \(F:(Q,I)\mapsto A^\prime\) used to predict the answer \(A^\prime\). Similarly, a Visual Question Generation (VQG) model \(G:(A^\prime,I)\mapsto Q^\prime\) is used to generate a rephrasing \(Q^\prime\) of \(Q\). The generated rephrasing \(Q^\prime\) is passed through \(F\) to obtain \(A^{\prime\prime}\) and consistency is enforced between \(Q\) and \(Q^\prime\) and between \(A^{\prime}\) and \(A^{\prime\prime}\).
Dataset

Does this harbor cater to luxury yachts or fishing boats?
Are there more yachts or fishing boats?
What type of boats are mainly in the harbour?
Would this harbour be better for yachts or fishing boats?

Do the pillows match the bedspread?
Does the bedspread match the pillows?
Is the pattern on pillows and bedspread similar?
Are the pillows matching the bedspread?

Are there any spices on the pizza?
Does the pizza have spices on it?
Is the pizza garnished with any spices?
Are there some sort of spices on the pizza?

Where is the nike sign?
Where can I find the nike sign?
Where is the nike sign located?
What is the location of the nike sign?

Is the horse running?
Does the horse appear to be running?
Does it look like the horse is running?
Is the horse in a running motion?

Is this in a cold climate?
Is the climate here cold?
Is a cold climate shown here?
Is the climate here frigid?

How high is the plane in the sky?
What altitude is the plane flying at?
How high up in the air is the plane?
Do you know the plane's current altitude?

Are the children related?
Are the kids related to each other?
Are the children relatives of each other?
Do those children come from the same family?

Would a vegetarian eat this meal?
If you were a vegetarian would you eat this meal?
Is this a meal a vegetarian would eat?
Would this be a meal a vegetarian would eat?

Was this food cooked in a oven?
Is the oven what the food was cooked in?
Was the food prepared in an oven?
Was the oven used to cook the food?

Is there a white horse running?
Is a white horse running in the picture?
Is there a horse that is white colored running?
Can you see a white colored horse running?

How many more hours until midnight?
Midnight is in how many hours?
What's the number of hours until midnight?
How many hours to go until it's midnight?

Which sign is for a fast food company?
What fast food company is this sign for?
The sign featured is for what fast food company?
What fast food company has this sign?

Is this a low calorie meal?
Is this meal healthy?
Is this a healthy meal?
Does the food look like a low calorie meal?
Dataset Format
VQA-Rephrasings contains 121,512 human-provided rephrasings for 40,504 original questions spanning 40,504 images from the VQA v2.0 validation dataset. The format of the questions is same as that of the VQA v2 dataset. Each question consists of one question from the VQA v2 validation split associated with 3 rephrasings. Each rephrasing has an additional fieldrephrasing_of which points to the question_id of the question it is a rephrasing of. More details about each field is provided in the schema table below. Consistency score as described in the paper can be found in the VQA-Eval repository.
{
question{
"question_id" : int,
"image_id" : int,
"rephrasring_of" : int,
"coco_split" : str,
"question" : str
}



