Principia: Training LLMs to Reason over Mathematical Objects
Our Contribution
This work develops an LLM evaluation benchmark and training data for reasoning problems whose answers are not numerical values or multiple-choice answers, but full mathematical objects.
The core claim is simple: if you want models that can help with real scientific and mathematical work, you need to train on such data & test whether they can derive things like equations, sets, matrices, intervals, and piecewise functions. We show that this ends up improving the overall reasoning ability of your model for all tasks.
Benchmark: PrincipiaBench on HuggingFace
Training data: Principia Collection on HuggingFace
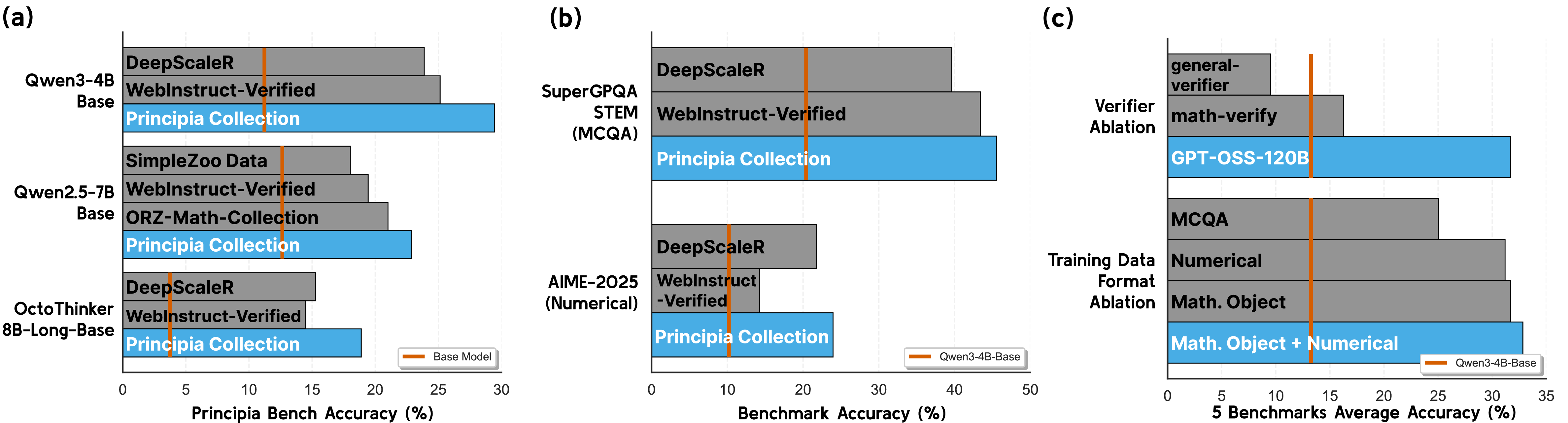
Figure: RL training on the Principia Collection improves performance on PrincipiaBench and transfers to numerical and MCQ benchmarks.
Why This Matters
A large fraction of current reasoning evaluation still rewards models for producing either:
- a numerical answer
- a multiple-choice option
Those formats are convenient to grade, but they hide important weakness: a model does not learn how to manipulate complex objects successfully, e.g. it can learn to solve a multiple-choice question (MCQ) by reasoning backward from the options rather than deriving the answer from first principles.
An example mathematical-object answer we work with looks like:
\[\frac{1}{|G|}\left(2 + \sum_{x \in G,\ x \neq 1}\mathrm{Re}(\chi(x))\right)\]That is a very different capability from selecting B from multiple choice questions, or outputting 42!
Existing Benchmarks Overstate Capability
Our experiments show that once answer options are removed from SuperGPQA questions that really require mathematical objects, performance drops sharply even for frontier models. The reported drop is typically in the 10 to 20 point range.
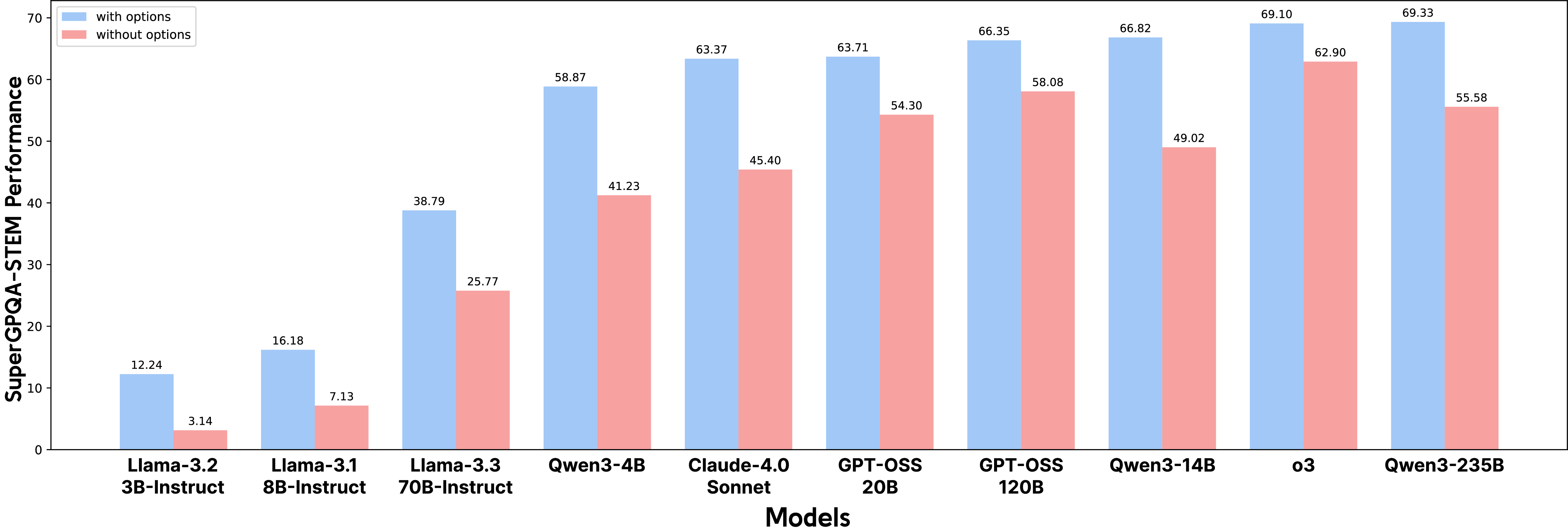
Figure: removing answer options reveals a substantial gap between MCQ performance and open-ended derivation ability.
This is the motivation for PrincipiaBench, a benchmark of 2,558 problems collected from RealMath, Physics, ARB, and filtered SuperGPQA items. The benchmark is designed so that the model must generate the mathematical object directly.
The Principia Collection
To train for this harder setting, we also introduce the Principia Collection, a 248K-example synthetic dataset grounded in:
- Mathematics Subject Classification (MSC 2020)
- Physics Subject Headings (PhySH)
These topic headings are sampled (e.g. ``Techniques for Polymers & Soft Matter » Resonance techniques » Nuclear magnetic resonance » Magnetic resonance imaging”) and are used to make challenging questions with sufficient diversity.
The target outputs span six answer types:
- equations
- inequalities
- intervals
- sets
- matrices
- piecewise functions
Here are some illustrative examples:
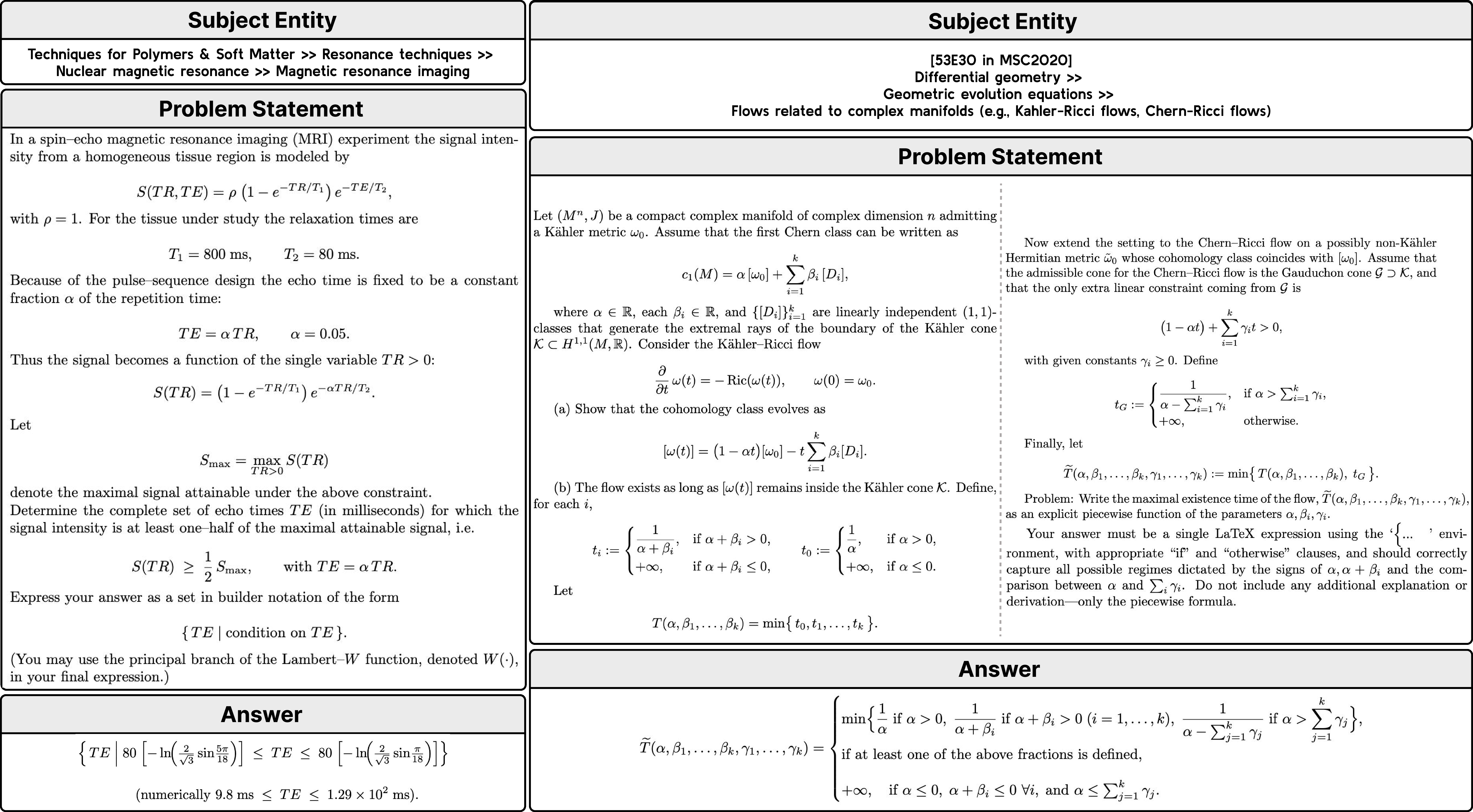
Figure: example instances from the Principia Collection, showing the level of detail and the mathematical-object answer types the dataset targets.
How we create the synthetic data
To create high quality data, there are a number of steps:
Step 1: Topic mining, as just discussed above.
Step 2: Problem Statement Generation. This process consists of three sub-stages:
- 2.1: First, for each subject entity, we sketch strategy descriptions that outline the core capabilities required to solve a problem. For each entity, we generate 40 descriptions.
- 2.2: Second, we iterate over each subject entity & capability pair to generate problem statements. In this step, one of the six mathematical object types is randomly selected as the answer type.
- 2.3: Finally, we include an additional refinement step to revise problem statements that resemble simple knowledge-probing questions, ensuring they require more genuine reasoning during the solving process.
Step 3: Filtering out Invalid Problem Statements. The filtering is based on three main criteria: (1) the problem statement must consist of only one question and be self-contained, (2) the problem should explicitly require the intended answer type, and (3) extensive hints or the answer itself should not be included in the problem statement. We prompt GPT-OSS-120B to evaluate all three conditions and retain only those instances that are judged as “Yes” for every criterion.
Step 4: Response Generation & Majority-Voting for mathematical objects. To obtain labels for the generated problem statements, we prompt GPT-OSS-120B eight times and apply self-consistency, taking the majority vote as the label. See the following figure:

Figure: illustration of the majority-vote procedure used to determine labels when multiple mathematically equivalent answers may be written in different forms.
Overall, we find this data creation procedure effective in increasing the conceptual depth of the generated problems and ensuring correctness.

Figure: Example of a subject entity (acquired from PhySH), a strategy description (from step 1), an initial problem statement and its corresponding CoT, and a revised problem statement and its corresponding CoT (from step 2).
Main Experimental Results
We conduct detailed experiments comparing various models on PrincipiaBench, including post-training various LM backbones with our training set, Principia Collection. The main findings of our experiments are:
- We find that strong LMs such as Qwen3-235B and o3 struggle on PrincipiaBench, achieving only 55.27% and 62.57% accuracy, respectively.
- Next, we use the Principia Collection, as an RL post-training dataset tailored to induce the ability to derive mathematical objects.
- RL training on the Principia Collection yields +7.52–18.23% improvements on PrincipiaBench across four different LMs.
- Moreover, LMs trained on Principia Collection improve by +7.08–20.10% on AIME-2025 (numerical) and +3.78–25.47% on GPQA-Diamond (MCQA), demonstrating cross-format generalization of reasoning abilities.
Comparison to other training datasets
We find that training on Principia Collection gives superior performance on reasoning problems involving mathematical objects of various types compared to existing training datasets, as measured by PrincipiaBench.

Figure: Training directly on complex mathematical objects yields substantially better transfer than training on datasets requiring only numerical values or simple mathematical objects.
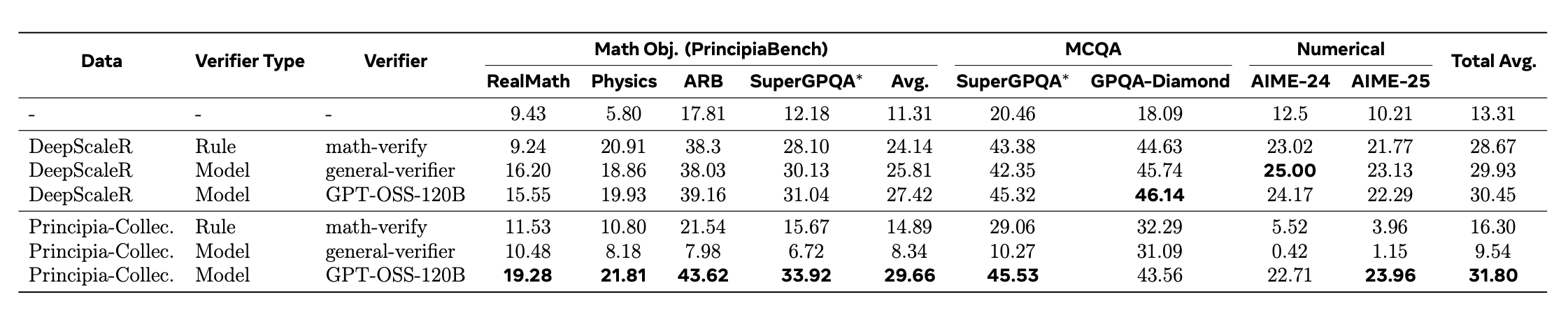
Importance of the Verifier
We find that training with a strong model-based verifier, rather than a rule-based verifier, becomes highly important when the data is more challenging to verify as in our training set. While there is little difference in terms of performance when training on DeepScaleR, which consists of numerical value and simple mathematical object answers, the performance varies a lot when training on the Principia Collection with consists of complex mathematical object answers.
Conclusion
The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. Likewise, existing RL post-training datasets overrepresent easy-to-verify formats, largely excluding complex mathematical-object answers.
To address these, we introduce the PrincipiaBench, a benchmark designed to evaluate an LM’s ability to derive mathematical objects, and Principia Collection, a synthetic post-training dataset which improves LLM’s on both PrincipiaBench and other reasoning tasks.
Together, the Principia suite provides a unified framework for evaluating and improving LM reasoning.
Contributors
Seungone Kim, Pranjal Aggarwal, Bo Liu, Swarnadeep Saha, Ping Yu, Anaelia Ovalle, Jack Lanchantin, Jing Xu, Weizhe Yuan, Wenting Zhao, Adina Williams, Marjan Ghazvininejad, Graham Neubig, Sean Welleck, Jason Weston, Ilia Kulikov.
More details
More details can be found in the full technical report.
Citation
If you use our training data or benchmark in your own work, please also cite with the following BibTex entry:
@article{principia2026,
title={Reasoning over mathematical objects: on-policy reward modeling and test time aggregation},
author={Pranjal Aggarwal, Marjan Ghazvininejad, Seungone Kim, Ilia Kulikov, Jack Lanchantin, Xian Li, Tianjian Li, Bo Liu, Graham Neubig, Anaelia Ovalle, Swarnadeep Saha, Sainbayar Sukhbaatar, Sean Welleck, Jason Weston, Chenxi Whitehouse, Adina Williams, Jing Xu, Ping Yu, Weizhe Yuan, Jingyu Zhang, Wenting Zhao},
journal={arXiv preprint arXiv:2603.18886},
year={2026}
}